A 5-minute cheatsheet outlining the challenges and solutions for building Large Language Models for production.
What are Large Language Models (LLMs)?
A Large Language Model, as the name implies, refers to a model trained on large datasets with the ability to comprehend and generate content. Essentially, it's a transformer model on a large scale. The transformer model itself is a neural network designed to grasp context and meaning through the analysis of relationships within sequential data.
What can LLMs do?
With LLMs, the possibilities are vast — from creating AI assistants and chatbots to engaging in conversations with your data and enhancing search capabilities. The potential applications are limitless.
What are prompts?
A prompt is the input given by a user, and the model responds based on that input. A prompt can be a question, a command or any kind of input, depending on what's needed for a particular use-case.
Prompt engineering, fine-tuning and embeddings
Prompt engineering is the practice of creating prompts that guide the model to produce the desired response. It's like influencing the model's thinking by shaping the input prompt to lead it towards a specific outcome.
Fine-tuning involves making a trained model more specialized for a specific dataset, refining it from its initial broader training. As an example, you might fine-tune a large language model using your own custom dataset.
Embeddings involve creating an array of numbers that encapsulate the meaning and context of specific tokens. These embeddings can be stored in a vector database.
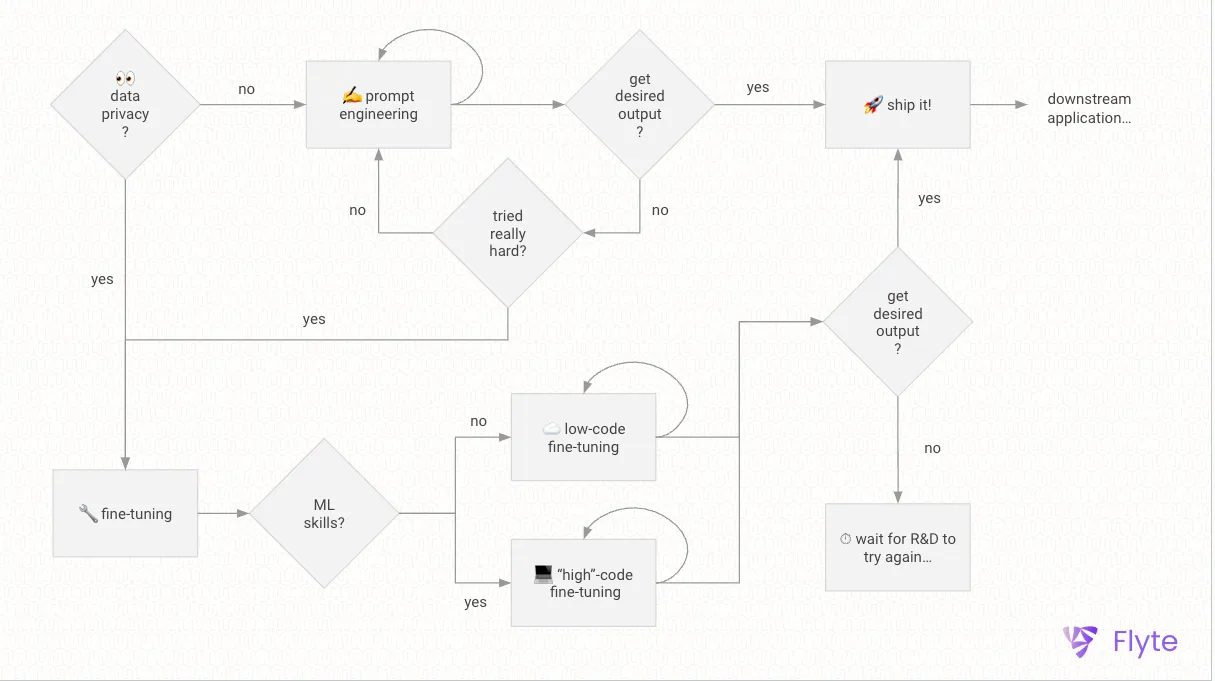
How to prompt-engineer an LLM?
Provide a prompt that's clear and covers all the necessary information. You can use Retrieval Augmented Generation (RAG), Chain-of-Thought (COT), zero- or few-shot prompting to optimize prompts. Simply send this prompt along with the expected input to the large language model, and you're good to go.
How to fine-tune an LLM?
Organize a dataset in line with the model's expectations and behavior. For instance, when fine-tuning an LLM to respond to customer service queries, it's essential to provide both a question and an answer pair to the model. The format of the prompt depends on the model's specifications; for example, the Alpaca model accepts an instruction, input and output pair.
Provide this dataset to a suitable model, select an appropriate fine-tuning strategy and initiate the fine-tuning process.
How to generate and store embeddings?
Generating embeddings can be achieved using readily available libraries such as OpenAI, HuggingFace, Cohere and more. These embeddings can be stored in vector databases like Chroma and Pinecone. Subsequently, you can retrieve the closest embedding to the provided prompt and then have the model generate the corresponding output.

What does it mean to build LLMs for production?
This can entail:
- Establishing an API to enable users to query the model, whether online or offline
- Crafting optimized prompts (context) to enhance output quality while also optimizing costs and latency
- Fine-tuning a Large Language Model
- Regularly generating and storing embeddings to keep the model up-to-date
Challenges of prompt engineering
- Identical prompts might not produce consistent outputs; the results are non-deterministic, unless intentionally enforced for uniformity
- It’s difficult to assess whether few-shot prompts are genuinely outperforming zero-shot prompts
- Optimizing prompts can be challenging due to the diverse approaches available for prompt optimization
- The longer the prompt, the greater the resource costs associated with it
Challenges of productionizing prompt engineering
- Non-deterministic outputs make it hard to maintain consistent results
- Maintaining a history of prompts to keep track of which prompt resulted in which output
Challenges of fine-tuning
- Creating a high-quality dataset that adheres to the model's expected format
- Navigating the trade-off between data quality and quantity
Challenges of productionizing fine-tuning
- Adjusting resource scaling based on the demands of the fine-tuning pipelines
- Establishing and allocating the essential infrastructure
- Maximizing GPU usage to minimize incurred costs
- Configuring optimizations for fine-tuning
Challenges of productionizing embeddings
- Generating and storing embeddings from time-to-time to keep the model up-to-date
Role of an orchestrator
An orchestrator like Flyte can help alleviate the challenges associated with productionizing LLMs
Prompt engineering
- Flyte lets you version pipelines, which in turn, lets you link prompts with specific workflow versions. This enables you to monitor which prompts led to specific outputs
Fine-tuning
- Flyte essentially functions as an infrastructure orchestrator, making autoscaling low-hanging fruit. In addition, using an orchestrator like Flyte makes it easy to use spot instances to reduce costs
- You can set up your dataset preparation and model fine-tuning as two distinct pipelines By harnessing the capabilities of an orchestrator, you can benefit from features like caching and data lineage, among others, while running your pipeline
- Flyte also lets you request the necessary resources on a task basis
- Union Cloud’s task-level monitoring feature offered in Union Cloud. This feature provides a clear overview of the extent to which allocated memory and GPUs are being utilized
- Perform fine-tuning, or training, using PyTorch elastic integration on either a single node or multiple nodes
Embeddings
Flyte makes it easy to work with embeddings. Use it to:
- Automatically generate embeddings whenever new data is available. Cache the existing stored data, and ingest only the newly arrived data
- Ingest embeddings into a vector database in parallel
In addition to these benefits, Flyte lets you:
- Leverage enhanced security for your large language models within the Flyte cluster, ensuring data ownership
- Scale your large language model applications across multiple teams
Optimization techniques for fine-tuning
For fine-tuning, the combination of appropriate optimizations and an orchestrator lays the foundation for constructing large language models for production.
Parameter-efficient fine-tuning
Parameter-efficient fine-tuning, or PEFT, focuses on fine-tuning only a small subset of additional model parameters, resulting in substantial reductions in both computational and storage costs. Remarkably, these techniques achieve performance levels that are comparable to full fine-tuning approaches. A widely used PEFT technique is Low Rank Adaptation, or LoRA. LoRA is an approach that trims down model size and computational needs by approximating large matrices through low-rank decomposition.
Quantization
Quantization is the process of reducing the precision of numerical data so it consumes less memory and increases processing speed. One library that may be of interest to fine-tuners is the bitsandbytes library, which uses 8-bit optimizers to significantly reduce the memory footprint during model training.

Zero-redundancy optimization
Zero Redundancy Optimizer, commonly known as ZeRO, harnesses the collective computational and memory capabilities of data parallelism. This approach minimizes the memory and computational demands on each device (GPU) utilized during model training. ZeRO accomplishes this by distributing the model training states (weights, gradients and optimizer states) across the available devices (GPUs and CPUs) within the distributed training hardware, thereby decreasing the memory consumption of each GPU.