Introduction
It’s been a journey. There have been users successfully running Flyte on Azure but, unfortunately, nothing publicly documented. It was more or less an urban legend.
But then came Tom Newton, Jan Fiedler, Terence Kent, and Chris Grass, all of them amazing Flyte users, contributors, and overall fantastic team players who not only managed to make it work on their infrastructure but were kind enough to contribute to Flyte some features that would pave the way for a more robust deployment:
- Support for Azure blob storage
- Support for Azure Workload Identity in fsspec
- Support for Azure AD authentication in stow, the Go library that Flyte uses to abstract away the blob storage layer.
- Support for Azure as a storage provider in Flyte’s Helm chart
- Support for pre-signed URLs (in progress)
This post will describe the components and design decisions behind a new Flyte reference implementation that uses Terraform/OpenTofu and leverages all the previous contributions to take you from an empty Azure Resource Group to a fully working Flyte cluster.
The storage layer
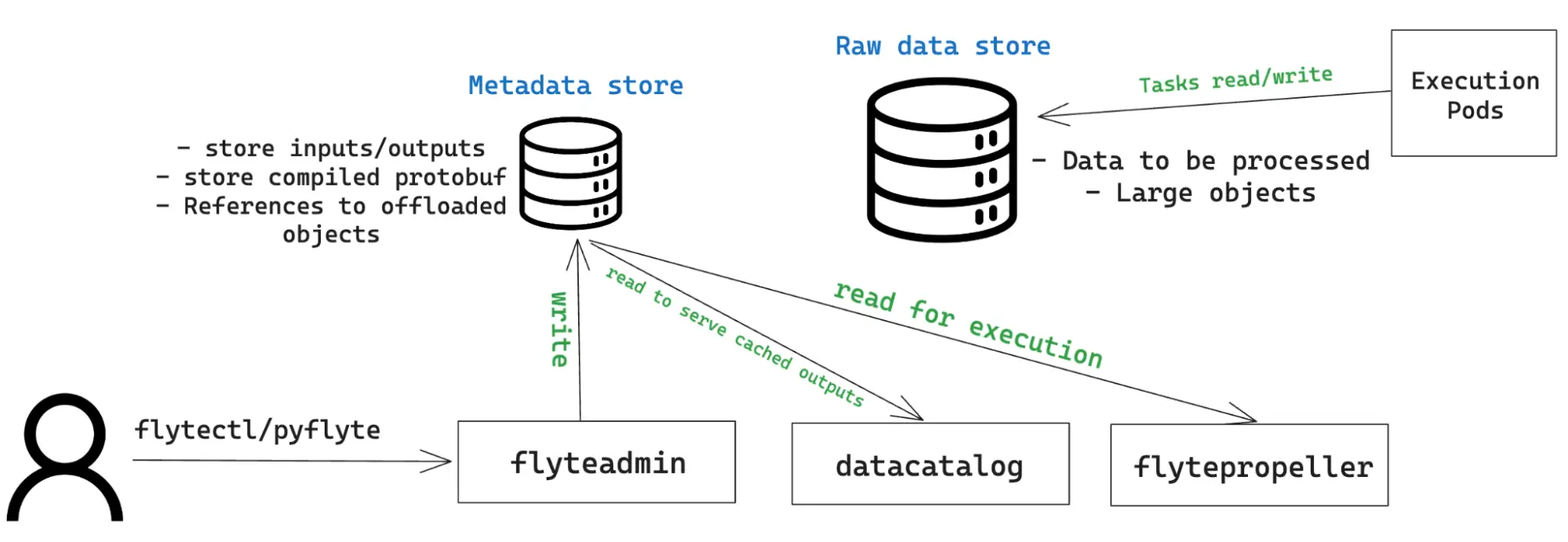
One of the key design requirements was to avoid insecure authentication methods like plain-text Storage Account keys or even Service Principal secrets. This is especially important for Flyte, as some of its components require write and read permissions to and from blob storage:

The Azure reference implementation creates a general-purpose v2 Storage Account with Hierarchical Namespace enabled. This ensures that the blob storage resource uses a file system-like structure and allows for granular permissions to be set at the directory or file level.
A default storage container is created and is used to store both metadata and raw data. You can instruct Flyte to consume exiting storage containers and/or to use separate buckets for metadata and raw data from the Helm chart.
The `azurerm` provider is configured to use Azure AD instead of Shared Access Keys to access blob storage resources with a valid identity.
The relational database
Flyte uses a Postgres database to store the inventory of resources under its management including registered workflows, launch plans, and projects. The reference implementation creates an Azure Database for Postgres flexible server instance version 15, and a corresponding `flyte` user with a random password passed to the Helm chart, which stores it on the `db-pass` Kubernetes secret. The instance type is the smallest Burstable with 1vCPU and 2GiB RAM. As suggested in the docs, pay close attention to metrics that could indicate contention in the database layer before considering scaling it up.
Identity management: the crux of the matter
To meet the requirement of using Azure AD-issued tokens instead of shared keys, the reference implementation uses Workload Identity:

Using the `azurerm` provider, the modules create two Azure user-assigned managed identities, one for the Flyte backend components (flytepropeller, flyteadmin, and datacatalog) and one for the pods where tasks are executed. The AKS workloads use these identities to register themselves to Entra ID.
For EntraID to emit a token, it needs to trust the requester. In this case, the connecting piece is a Federated Identity Credential. The Terraform modules create several of them: one for each of the Flyte backend components and one for every project-domain combination.
The Federated Identity Credentials establish a trust relationship between a Kubernetes Service Account (KSA) and an application—in this case, a user-assigned identity. Similar to every Flyte backend component using a particular Service Account, the User Pods leverage the `default` Service Account specific to every `project-domain` namespace, unless you instruct Flyte to use a different Service Account by using pyflyte run —-service-account. In that case, you must create a Federated Identity Credential with that KSA as the subject.
The other parameter that the Federated Credential needs is the URL of the Identity Provider, the system that will issue the OIDC tokens. In this case, this role is accomplished by the AKS cluster itself, completing the cycle for AKS workloads to be able to authenticate to EntraID and obtain an identity token that represents them throughout the Azure Resource Group.
While the previous process covers authentication, it doesn’t indicate what, once logged in, an application can do on Azure. The authorization mechanism is completed with the Role Assignments where every user-assigned identity is granted the Storage Blob Data Owner built-in role that enables full permissions on any containers under the Storage Account.
Similar to other cloud providers, the connecting element here is an annotation on a Kubernetes Service Account. Every Flyte backend component and user pod has its corresponding Service Account annotated (see flyteadmin, for example) and the pod is configured with a label required for Workload Identity to work. For every pod that meets these requirements, the Workload Identity Admission Webhook will trigger the process to request and inject an OIDC Identity Token into the resulting spec.
A quick inspection into a user pod confirms that both the necessary environment variables and projected token volume are correctly added to the spec:
The compute layer: CPUs and accelerators
The resources in `aks.tf` deploy an Azure Kubernetes Cluster with the latest stable Kubernetes release and automatically configure your local kubeconfig context to point to the newly created cluster. By default, this Terraform config creates a single node pool with one Standard_D2_v2 instance with 2 vCPU and 7 GB RAM. The node pool is configured to scale out up to a maximum of 10 instances automatically.
The locals array is where you can specify the AKS cluster to include GPU-enabled nodes (disabled by default). If you set locals.gpu_node_pool_count to a number higher than zero, it will trigger the creation of a new node pool under the same AKS cluster, using a default Standard_NC6s_v3 instance type with 6 vCPU, 112 GB RAM, and 1 NVIDIA Tesla V100 GPU. You can change any of the parameters in the array, with the following considerations:
- locals.accelerator cannot use arbitrary names but one of the constants supported by flytekit:
- {{flyte-azure="/blog-component-assets"}}
- To consume GPU partitions, currently supported in flytekit for the NVIDIA A100 model, you don’t need to specify a locals.accelerator key but to set the locals.partition_size to match one of the NVIDIA-supported instance profiles.
Additional resources deployed when you enable the GPU node pool include NVIDIA’s GPU Operator. This component automates the installation of the Kubernetes device driver, NVIDIA container toolkit, and node labeling, among other prerequisites. This means the user doesn’t have to install anything manually to consume GPU accelerators in AKS.
The README page covers three ways to request GPU accelerators: a generic GPU, a specific accelerator, and GPU partitions for optimal resource usage.
Learn more about all the options Flyte gives you to request GPU accelerators from your code.
Ingress and TLS: networking and security layer
Ingress is a Kubernetes-native resource designed to provide a central connection endpoint that routes requests to specific services depending on path rules. It can be declared to the Kubernetes API, but the declaration is not fulfilled until there’s an Ingress controller available, something that’s not provided by Kubernetes itself, but by third parties. This reference implementation deploys the NGINX Ingress controller and configures the Helm chart to request an Ingress resource. The controller will provision an Azure Load Balancer with a public IP address and a DNS alias, which is the URL you will use to connect to Flyte via the UI or CLI.

The Ingress controller configuration includes an Azure-specific annotation that ensures the health probe points to /healthz. The controller sends a request to this path to verify the application's health status.
Also, the `connect_flyte.sh` script, executed automatically at the creation of the Ingress controller, obtains the public IP address assigned to the load balancer and associates it with the DNS label, which corresponds to the `flyte_domain_label` key that you can change from the default `flyte` in locals.tf.
Establishing a secure communication channel to your Flyte cluster is performed by configuring a Transport Layer Security certificate issued by Let's Encrypt. The Ingress resource will use the certificate to terminate the SSL connection so you can safely connect to the cluster from the browser or the CLI. The process is automated using cert-manager, a controller that “listens” to certificate requests and manages the certificate’s lifecycle. When the certificate is close to expiring, you will receive a notification from Let’s Encrypt at the `email` configured in `locals.tf`.
Storing images in Azure Container Registry
The `acr.tf` module creates an Azure Container Registry and grants push permissions to the user currently logged in through the az cli. In this way, all the user has to do is to run az acr login -n <REGISTRY_NAME> and they will be able to push images to ACR.

Every Flyte workflow execution uses a default container image. If you plan to use a custom image stored on ACR, the module also grants Acrpull permissions to every workload on the AKS cluster so the pods created with task executions can pull the custom image from ACR.
Conclusion
We hope this set of Terraform/OpenTofu modules helps you get started quickly with Flyte on Azure. Your feedback is important and contributions are welcome. If you have any issues or questions, reach out to the community at #flyte-on-azure on Flyte’s Slack.