Large language models (LLMs) have taken the world by storm, revolutionizing our understanding and generation of human-like text. These models have showcased remarkable capabilities across a range of tasks, including question-answering, chatbots and even creative writing. Naturally, like many others, I was filled with excitement to explore and experience the potential of these models firsthand.
As an open-source contributor at Union, my aim was to enhance users’ ability to find solutions to their queries independently on Slack.
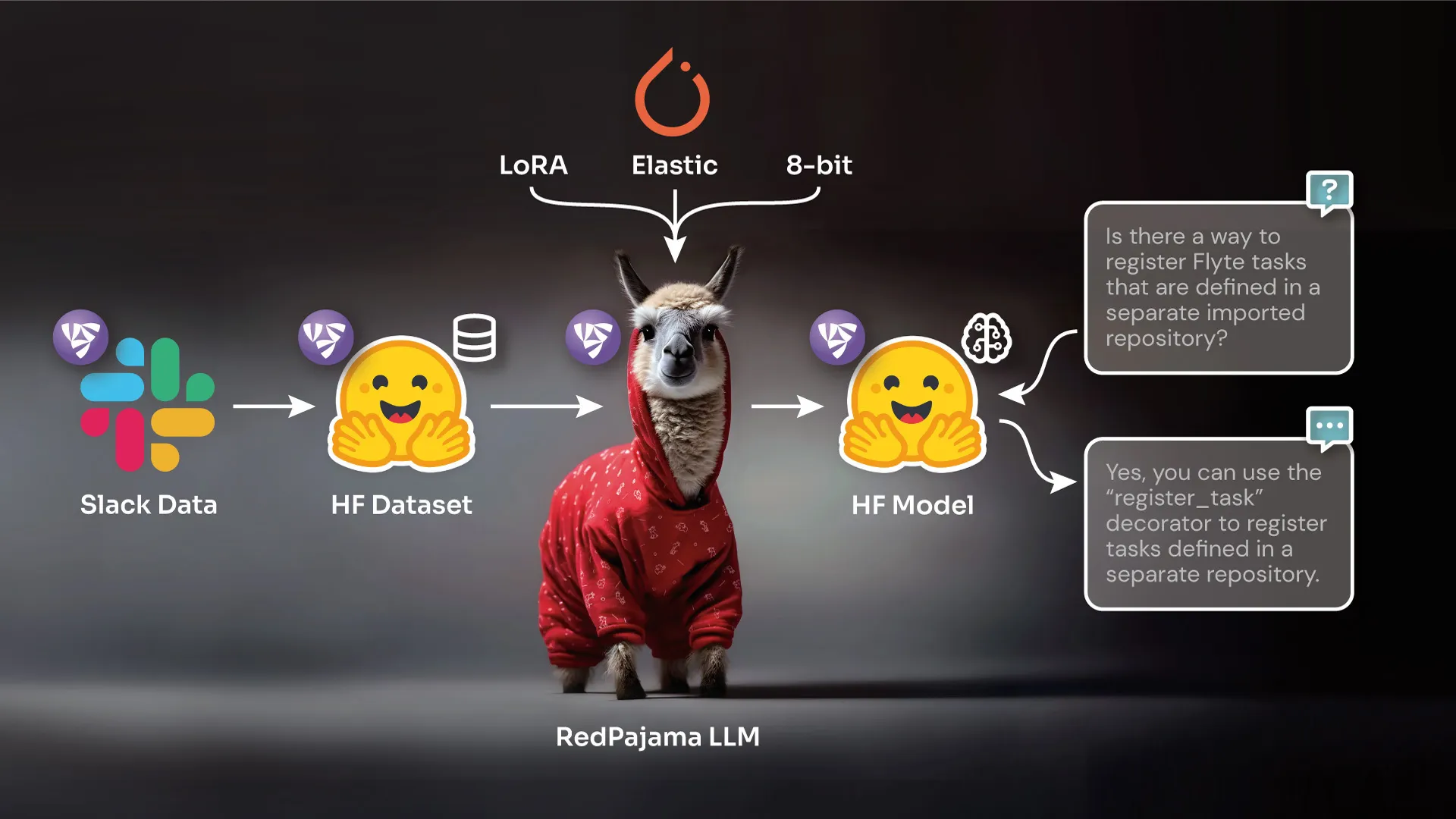
Building upon this goal, I had the Flyte Slack data on hand, and I set out to fine-tune an LLM using that data. My ultimate objective was to develop a Slack bot that could run within the Flyte Slack workspace.
Instead of relying on embeddings, which have already been extensively explored, I opted for (supervised) fine-tuning to examine its performance and potential benefits. This decision was driven by my desire not only to incorporate knowledge into the model but also allow it to learn the subtleties and nuances of Slack messages. Fine-tuning appeared to be the better option for achieving this objective.
While fine-tuning itself proved to be a straightforward process, I was surprised to discover that the surrounding factors and implications turned out to be much more complex than I had anticipated …
Slack scraper
Goal: Create a scraper that extracts data from Slack channels and saves it on HuggingFace. The extracted data will be used later for fine-tuning an LLM.
Data is vital for fine-tuning LLMs — or any other model, for that matter. Therefore, the first crucial step is to extract Slack data and generate a dataset from it, finding a way to store it appropriately.
I exported all the Slack data into a folder, which consists of directories that align with each Slack channel. Within each channel directory, there are neatly arranged JSON files, in which each file represents the data for a specific day.
Sample JSON data
I proceeded to write a Flyte task that retrieves the names of the directories, or channels, within the parent directory.
Next, I developed a task that extracts question-response pairs from the Slack data, involving the organization of messages into coherent threads. Within each Slack thread, I extracted question-response pairs, ensuring that a question corresponds to one user and the response corresponds to a different user. In cases where the same user posted multiple consecutive messages, I combined them into a single question or response.
This approach allowed me to retrieve multiple question-response pairs from each Slack thread, which made more sense to me than considering the first message to be the question and the remaining messages to be the response. Considering the possibility of multiple users contributing to a single Slack thread, it was important to capture the various contexts within the conversation.
Finally, the resulting question-response pairs were stored in a JSON file.
This task is applied to all the channels, and the resulting question-response pairs are stored in individual JSON files. Next these files are merged together to create a comprehensive dataset, which is then saved on HuggingFace for further use and analysis.
I have accumulated a substantial amount of data, totaling approximately 28.2k rows! You can analyze and use this dataset as needed.

At first glance, the large size of this dataset instilled a sense of excitement, raising expectations for the LLM to deliver impressive performance. However, there are a few gotchas to keep in mind:
- Outputs as inputs: It's crucial to note that the outputs from previous question-response pairs are treated as inputs for subsequent pairs. This chaining of information can impact the model's understanding and generation of responses.
- Terse responses: Responses on Slack can often be brief and lacking in detail. This brevity can pose a challenge for the LLM, as it may struggle to provide comprehensive or informative answers.
- Inaccurate responses: Not every response in the dataset can be guaranteed to be an accurate answer to the corresponding question. Some responses may diverge from the intended answer or may not fully address the question's intent.
- Non-question inputs: It's important to acknowledge that not all inputs labeled as questions within the dataset are necessarily genuine queries. Some labeled questions might be statements, comments, or incomplete phrases, which may impact the model's performance.
I proceeded with the fine-tuning of the LLM regardless.
Fine-Tuning RedPajama LLM
Goal: Fine-tune the RedPajama LLM using the collected dataset, refining its ability to provide responses to queries within the Flyte Slack platform.
I chose the RedPajama 7B chat model for fine-tuning. As for the prompt, I decided to go with the following:
To carry out the fine-tuning process, I utilized the PyTorch elastic training integration, running the code on a single node equipped with five T4 GPUs. This integration provided a seamless way to utilize any PyTorch elastic training runner and its associated integrations effortlessly on Union Cloud. It provided a convenient approach to train any LLM, allowing for a straightforward replacement of the `torchrun --nproc-per-node=1 --nnodes=1 …` script with a simple `@task(task_config=Elastic(nnodes=1))` annotation.
Flyte task configuration
Moving forward, the subsequent step entails loading the tokenizer and LLM model into memory to proceed with fine-tuning.
By utilizing the `device_map="auto"` parameter, I can leverage Hugging Face Accelerate to automatically determine the optimal placement of each layer in the model based on the available resources. This approach maximizes the utilization of GPU memory space by initially storing the model's weights on the GPU(s). If additional space is required, the remaining weights are stored on the CPU. In cases where there is insufficient RAM, the excess weights are stored on the hard drive as memory-mapped tensors.
Running the 7B model in full precision requires a total of 28 GB (7 * 4) GPU RAM, considering that each single precision (float32) floating-point number occupies 4 bytes of memory. However, the T4 instance I'll use for fine-tuning has only 16 GB of GPU memory available. To ensure that the model fits within the available memory, I set `torch_dtype` to `torch.float16`. By using half precision, the memory footprint is reduced to approximately 14 GB, allowing the model to fit within the available 16 GB of GPU memory on the T4 instance.
To further minimize memory consumption, which may not be necessary in this particular case but can be beneficial for larger models, you can employ 8-bit or 4-bit quantization offered by the bitsandbytes library. This approach allows for even more efficient utilization of memory resources. By utilizing the `load_in_8bit` functionality, I can convert the loaded model into a mixed 8-bit quantized model. This feature enables the model to be loaded and operated with reduced memory requirements while maintaining acceptable performance.
After loading the model in 8-bit precision, the resulting memory footprint is as follows:
The model only occupies 7.4GB of memory!
Note: If the `torch_dtype` is not specified when loading the model in 8-bit, you will encounter the following warning:
You can also use Parameter-Efficient Fine-Tuning (PEFT) techniques to address the challenges posed by computational and storage requirements. PEFT focuses on fine-tuning only a small subset of additional model parameters, resulting in substantial reductions in both computational and storage costs. Remarkably, these techniques achieve performance levels that are comparable to full fine-tuning approaches.
I will be utilizing a PEFT method called Low Rank Adapters (LoRA) from the PEFT library. Instead of fine-tuning the entire model, LoRa enables fine-tuning of specific adapters, which are then appropriately loaded within the model.
Before training the int8 model using PEFT, there are some pre-processing steps that need to be performed. To help with this, I will incorporate a utility function called `prepare_model_for_int8_training` that performs the following tasks:
- It casts all the non `int8` modules to full precision (`fp32`) to ensure stability during training.
- It adds a `forward_hook` to the input embedding layer, enabling gradient computation of the input hidden states. This is important for accurate gradient calculations.
- It enables gradient checkpointing, which optimizes memory usage during training by selectively storing and recomputing intermediate activations.
LoRA and PEFT
The next step in the process is to define a `Trainer` that will handle the training loop.
HuggingFace Trainer to fine-tune RedPajama using Slack data.
I stored the resulting fine-tuned model LoRA weights on the Hugging Face models hub for easy accessibility and future use.
You can access the complete fine-tuning code on our GitHub repository. The code includes various libraries and techniques, such as PyTorch elastic training for native `torchrun` usage, 8-bit quantization, PEFT and LoRA. By integrating these techniques into a Flyte task, I successfully conducted the fine-tuning process on T4 GPUs, leveraging the capabilities of Union Cloud as a unified platform. Union Cloud offers a secure environment, deployed within your virtual private cloud (VPC), to ensure you have full control over data access. It lets you reproduce your fine-tuned model artifacts and facilitates easy retrieval whenever needed.
Inference
Goal: Implement an inference pipeline using the fine-tuned RedPajama LLM to generate accurate predictions on new user queries.
During the inference phase, I retrieved the pre-trained model and instantiated a LoRA model using the pre-trained LoRA configuration and weights.
The predictions I generated were suboptimal.
{{RedPajama-qa="/blog-component-assets"}}.
It seems that the prompt I used could have been more effective. RedPajama recommended an alternative prompt, but unfortunately, it did not yield improved results Interestingly, I also noticed a significant number of empty outputs for some unknown reason.
Key takeaways
I observed that the performance of the fine-tuned model did not meet my initial expectations. The responses generated by the fine-tuned model tended to be concise, and there were occasional repetitions in the output.
The brevity of responses can be attributed to the characteristics of the Slack data used for training. To address this, one possible approach could be to filter and consider only longer responses or involve human intervention to select and provide appropriate responses.
Regarding the issue of repetitions, it seemed to stem from the model being undertrained, as the training loss plateaued while the evaluation loss continued to decrease. Although I attempted to mitigate this problem by applying a repetition penalty, it did not completely eliminate the repetitions.


Interestingly, when I fine-tuned the model on a smaller subset of 1,000 data samples instead of the entire dataset, the responses became longer, although the model occasionally generated hallucinated content. Nevertheless, the responses remained polite and detailed.
Fine-tuning seems like a promising approach, but its effectiveness heavily relies on the availability and quality of the data. However, considering the requirement for high-end GPUs solely for training purposes, it may not be the most efficient use of resources. When fine-tuning, it is important to anticipate the response style that aligns with the output format of the training dataset. I noticed that the fine-tuned model often heavily relied on the specific characteristics of the training data, sometimes disregarding the desired response style (even after modifying the prompt to guide it toward generating detailed explanations.)
In contrast, generating semantic embeddings proved to be a quick, straightforward and effective alternative in most use cases. This cost-effective solution allows you to harness the power of larger and more advanced models like GPT to generate embeddings. Since embeddings operate as distinct modules, they retain the pre-trained knowledge and are less prone to catastrophic forgetting, unlike fine-tuning, which can lead to the loss of previously learned information while adapting to new tasks. When the objective is to impart knowledge to the model, embeddings provide a more consistent response style, primarily focusing on delivering factual information in most cases.
To summarize my experimentation journey and key takeaways: I initially began fine-tuning the model with a limited understanding of dataset curation and prompt engineering. I quickly learned that the quality of the dataset plays a vital role in the fine-tuning process. On the other hand, dealing with embeddings proved to be relatively simpler and didn't require extensive dataset cleanup, although it never hurts to ensure cleanliness.
Moving forward, the next steps involve deciding between fine-tuning and utilizing semantic embeddings. If fine-tuning appears to be a suitable approach, I will proceed with the creation of a high-quality Slack dataset. I would greatly appreciate your feedback and any ideas you may have regarding improvements or further steps that I could consider.
Originally published at https://allasamhita.medium.com.