Artifacts provide a core abstraction that serves as an interface between the different teams that work together to build AI-powered products.
This post demonstrates specific workflow orchestration patterns that help you and your teams manage AI/ML applications.
Orchestration for the AI era
In the world of software, orchestration addresses the general problem of getting a job done by leveraging the appropriate set of compute resources, sequenced and executed in just the right way. Orchestration tools and the set of capabilities they enable are anchored by the needs of the time and the nature of the problems that their builders aimed to solve.
The `make` utility—which you might consider a proto-orchestrator—was born at a time and place when programmers needed to build their statically compiled programs with complex sets of dependencies on their local machines. The Airflow data orchestrator was created during the ETL data engineering era, optimized for processing batch data, maintaining and backfilling database tables, and keeping data fresh on a regular cadence using cloud infrastructure. Kubernetes, a container orchestrator, came out of the need to manage complex, containerized applications in the world of microservices.
We are building Union in the era of machine learning and artificial intelligence, which requires high quality up-to-date datasets, training and scaling models on GPUs, fast experimentation cycles, and use-case-dependent model serving. For many organizations we’ve worked with, we’ve learned that an AI orchestrator needs the following properties:
- Baked in reproducibility via containerization.
- Type safety enforced between nodes in the graph.
- Automatic handling of data flow between nodes in the graph.
- Declarative provisioning of heterogeneous compute (CPUs, GPUs, etc).
- Multi-tenancy, resource isolation, and massive scaling of compute.
- Data and models as first-class entities.
- Softly-coupled microservices bound by data and models.
- Support for multiple model inference modalities.
We’ve learned a lot of lessons building and maintaining Flyte, an Kubernetes-native orchestrator, which covers properties 1-5 really well. Flyte has been running in production at companies like Spotify, Stripe, and ZipRecruiter, enabling them to increase their iteration speed and deploy ML/AI-powered products at scale. Based on our experiences, we’re learning a lot about what organizations need out of their orchestrator when data and AI are at the center of it.
In the rest of this post, we’re going to talk about how artifacts and reactive workflows unlock requirements 6 and 7 in the list above. In order to do this, we’ll need to install Union’s SDK, `unionai`:
This SDK builds on top of `flytekit` to unlock additional capabilities on the Union platform:
Data and models as first-class entities
Flyte is already data-aware in the sense that it leverages function type hints and abstracts the data flow between nodes in the execution graph. However, one of the limitations of Flyte is that it treats only functions as first-class entities and assumes that your data and modeling workflows are composed of strongly coupled units of compute. In other words, Flyte sees your datasets and models as outputs of functions, which can then be consumed directly by downstream functions.

In order to interact with the datasets and models directly, e.g. in a REPL, you have to do something like:
In the code snippet above, it’s clear that Flyte treats the `model` as the output of a function that’s been executed, uniquely identified by `execution_id`.
But what if you don’t want to strongly couple the dataset creation step and model-training step? This is common in many organizations that have a division of responsibilities, where a data team produces datasets that serve multiple purposes, an ML team consumes those datasets for their modeling, and an analytics team consumes them for reporting.
For example, the data team might maintain a set of tasks and workflows that produce an ML-specific dataset and an analytics-specific dataset:
Then, the ML team consumes the ML dataset for a particular use case.
These two teams operate in different repositories and might have completely different ways of managing their source code and deploying their applications, but they still need to share datasets and models with each other.
In Flyte, you might achieve this by creating custom code that uses `FlyteRemote` to stitch together different workflows:
There are three main problems with this:
- Flyte has no way of understanding the lineage between `create_ml_dataset` and `train_model`, and thus traceability and auditability suffers.
- You now have to maintain scripts that are outside of Flyte’s understanding in terms of how different tasks are composed together.
- To get the latest materialization of the dataset, you need to write more code to find the latest execution of a task execution.
Flyte’s existing solution to this problem is to use reference tasks and caching so that the ML team can effectively import a cached version of the dataset:
The Flyte workflow pipeline might look something like this:

From a functional programming perspective this is quite nice because we can effectively retrieve the cached `dataset` output of `create_ml_dataset` that has already been computed by the dataset team. However, the ML team needs to make sure they have the correct `project`, `domain`, `name`, and `version` of the task from the data team. They also need to make sure that the function input and output signatures are consistent with how the data team has written the task on their end.
This ceremony introduces additional overhead for ML teams who just want to consume the freshest data for their models.
Using the freshest data to train your models
While tasks and workflows are a great abstraction for understanding how something was created, ultimately they are a means to an end. In the case of ML, the end is the dataset produced by the data engineering team and the models produced by the modeling team. Union introduced artifacts to simplify cross-team collaboration so that sharing these outputs is as easy as knowing the string name that references them.
Instead of using `FlyteRemote` or reference tasks as shown above, the data team can simply create an `Artifact` as follows:
As you can see, `flytekit` uses python’s `Annotated` type to attach additional metadata to the output of tasks. The output of `create_ml_dataset` is no longer just a `pandas.DataFrame`: It is also an `MLDataset`, which Union now understands as a first-class entity.
Then the data team simply has to communicate the name of the `ml-dataset` artifact to the ML team who can then consume the dataset as follows:
By stating that the default argument to the `training_workflow` is `MLDataset.query()`, the ML team effectively creates a soft dependency between `create_ml_dataset` and `training_workflow`. This means that running the training workflow will automatically use the latest version of the `ml-dataset` artifact.

Key-partitioned model training
Suppose that your application requires training models that are partitioned by region, which means that we need to create region-specific datasets as well.
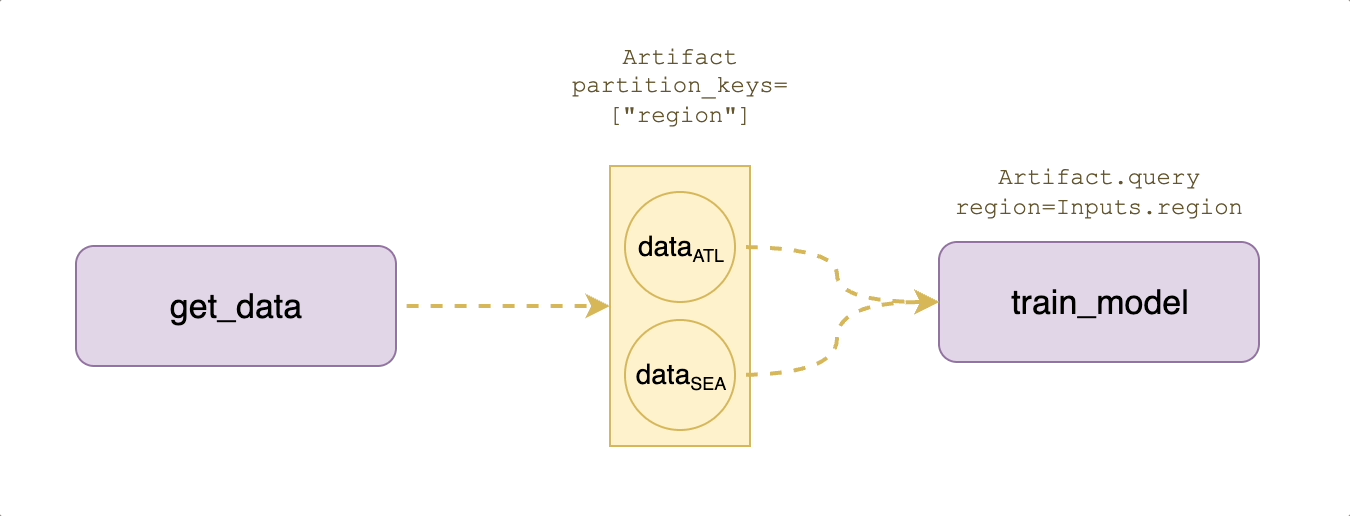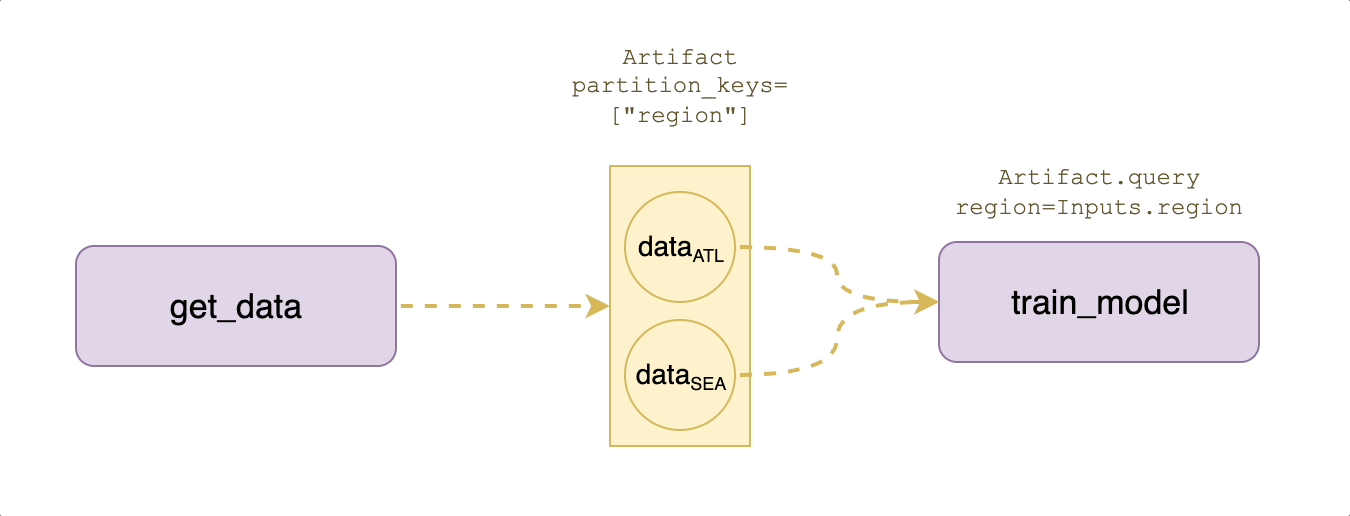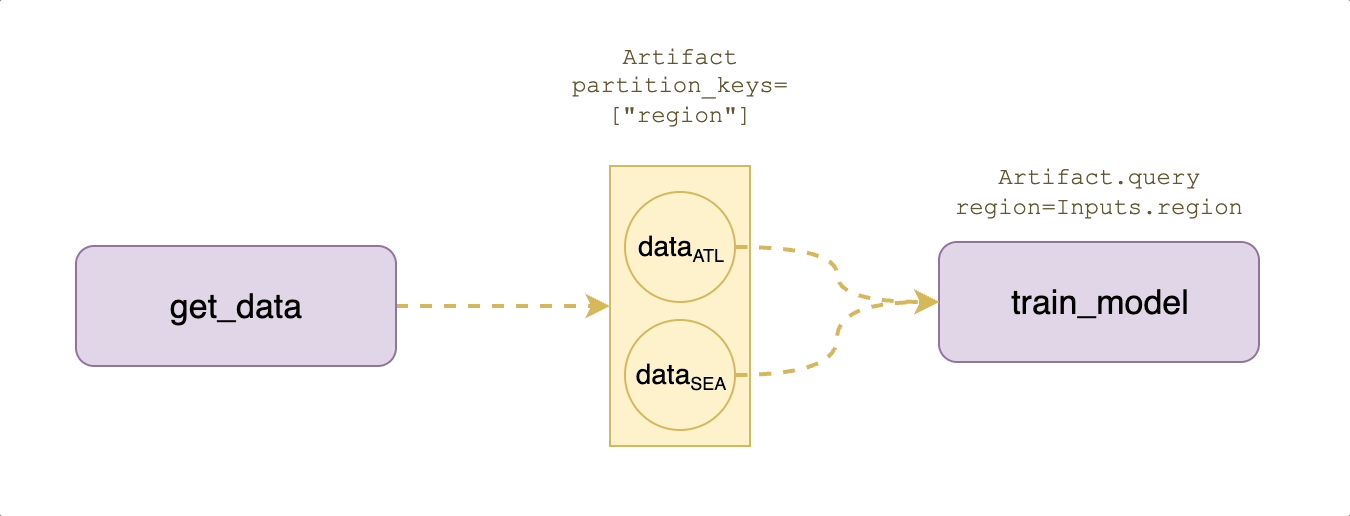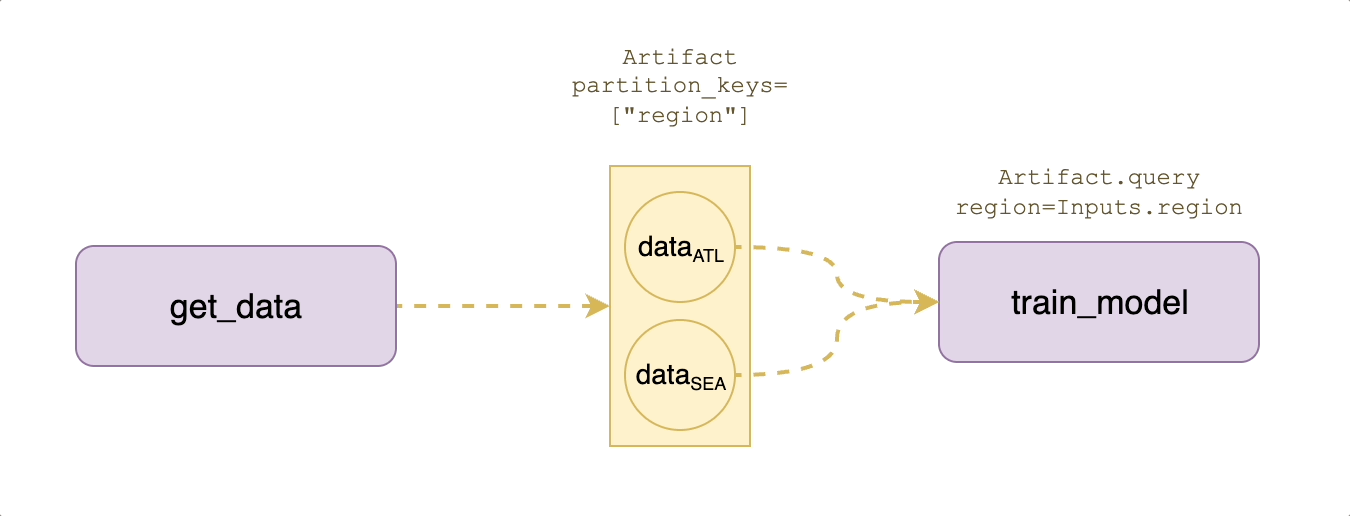
As shown in the diagram above, the Artifacts abstraction provides a `partition_keys` argument to logically separate the data by use case:
In the output signature of `create_ml_dataset`, we basically say that the returned artifact is `MLDataset(region=Inputs.region)`, which means the region partition value is whatever the `region` input string was at task execution time.
Now the ML team can create a model artifact that’s region-specific. In its simplest form, the conditional branching can be implemented at the task-level:
This supports any arbitrary string partition based on your use case, e.g. you can define a `user_persona` partition key if you want to train models based on the type of customer on an e-commerce application. Other ways you can leverage this capability be would to:
- Create a `splits` partition with `train`, `validation`, and `test` values if you decide that strictly maintaining data splits at the artifact-level is mission critical for your team.
- Create shadow deployments by publishing an artifact with a `deployment_type` key with `shadow` and `production` values. These can be consumed by batch workflows and treated accordingly in the workflow/task definition.
Reactive Workflows
Artifacts aren’t just static entities that you use to conveniently fetch data and model objects: they are also the basis of Union’s event-driven orchestration. They enable you to express softly-coupled execution graphs through reactive workflows. These are workflows that can subscribe to a specific artifact and are triggered based on the publication of a new artifact version.
The reactive workflow pattern is especially useful in the AI development lifecycle because of the different time scales that each stage operates in:
- Datasets can be churned out at variable velocity depending on the application, e.g. high quality, expert-labeled image datasets (slow) vs. real-time stock market price dataset (fast).
- Model development is typically highly iterative but the velocity of new models depends on the context, e.g. large deep learning models on internet-scale data (slow) vs. small models on medium-sized tabular data (fast).
- Model deployment velocity is also application-dependent. There may be a long lead time between model releases depending on the relative safety and evaluation requirements of the application, e.g. entertainment (low safety requirement) vs. healthcare (high safety requirement).
Reactive workflows provide the flexibility to decouple the stages of the AI lifecycle where the next stage “just happens” whenever an upstream dependency is materialized.

The use cases below illustrate how you can leverage reactive workflows in the AI/ML development lifecycle.
Automated time-partitioned model evaluation
Model evaluation is arguably the most important part of the AI/ML product lifecycle. For time series models, this is even more important to get right because you can inadvertently leak privileged “future” information in the training set. The popular scikit-learn library even has a TimeSeriesSplit abstraction that helps make sure your training and test sets are correctly partitioned.

With artifacts, you can fulfill this use case by creating a `time_partitioned` artifact. Suppose that you want to backtest a weather forecasting temperature estimation model that was retrained hourly. Whenever you train a model at hour `t`, you want to train on all the data `t-1` and test on the data collected at `t`. To do this, you can define a reactive workflow.

The data team would create a dataset on a regular schedule like so:
Here the data team uses a `LaunchPlan` to create a dataset every hour, partitioned by the `kickoff_time` of the workflow.
Then, the ML team can consume the artifact and make sure to get both the latest version of the dataset and previous version of the dataset.
Let’s walk through what’s happening here:
- This workflow uses `OnArtifact` to determine when the `auto_backtest` launchplan should run via the `trigger_on` argument. Here we’re saying to trigger the launchplan whenever the `TimeSeriesData` artifact changes.
- Then, it can determine what `inputs` to provide by getting the most recent materialization of T`imeSeriesData` and the previous materialization through `TimeseriesData.query(time_partition=...)`.
- The launchplan then calls `backtest_workflow`, which produces a `Module` containing the backtested model.
- When the launchplan is triggered, the underlying `backtest_workflow` gets the dataset of the current time partition and the one from the previous time partition.
- Then, the `backtest_model` task splits the dataset into training and test sets to make sure the test set is correctly split by the `”timestamp”` column.
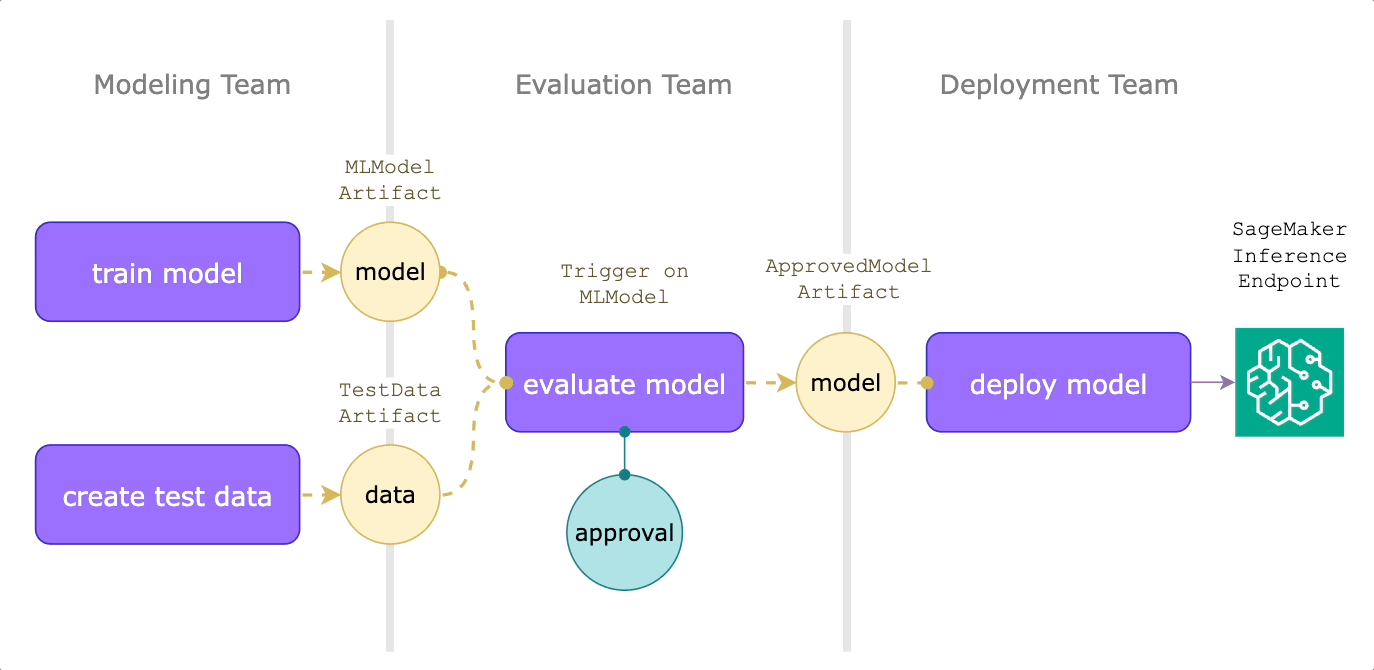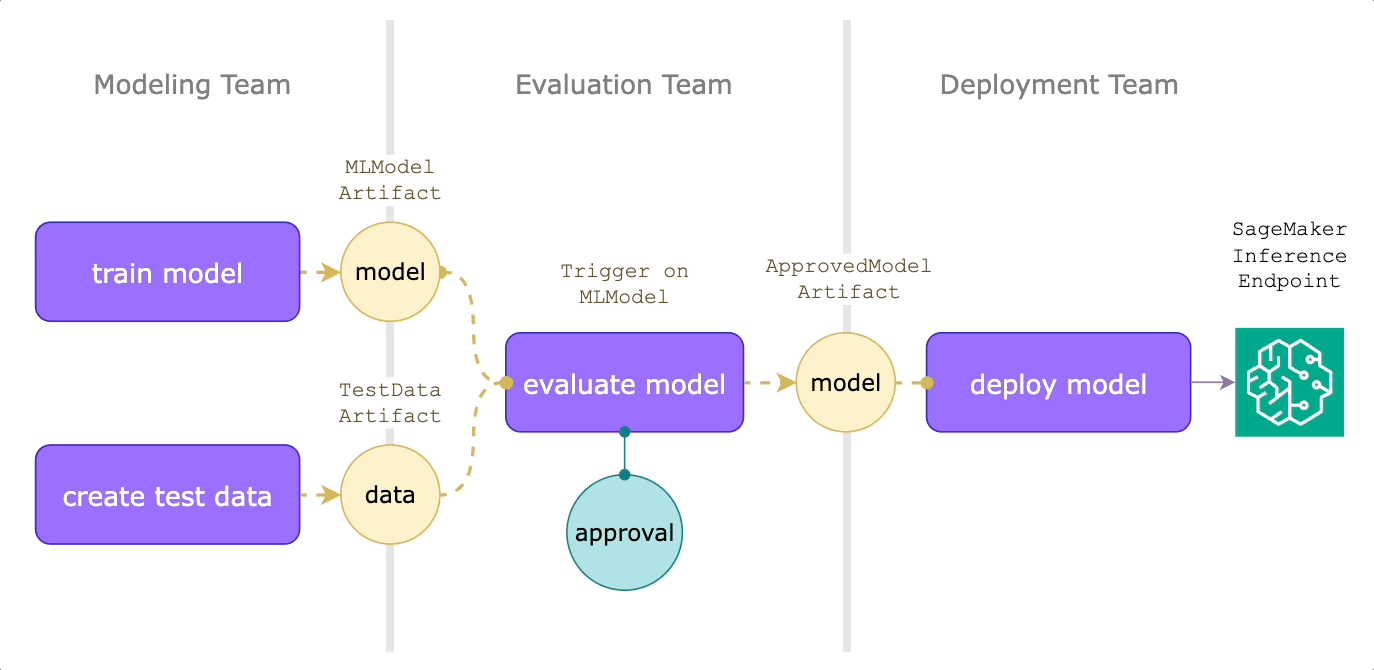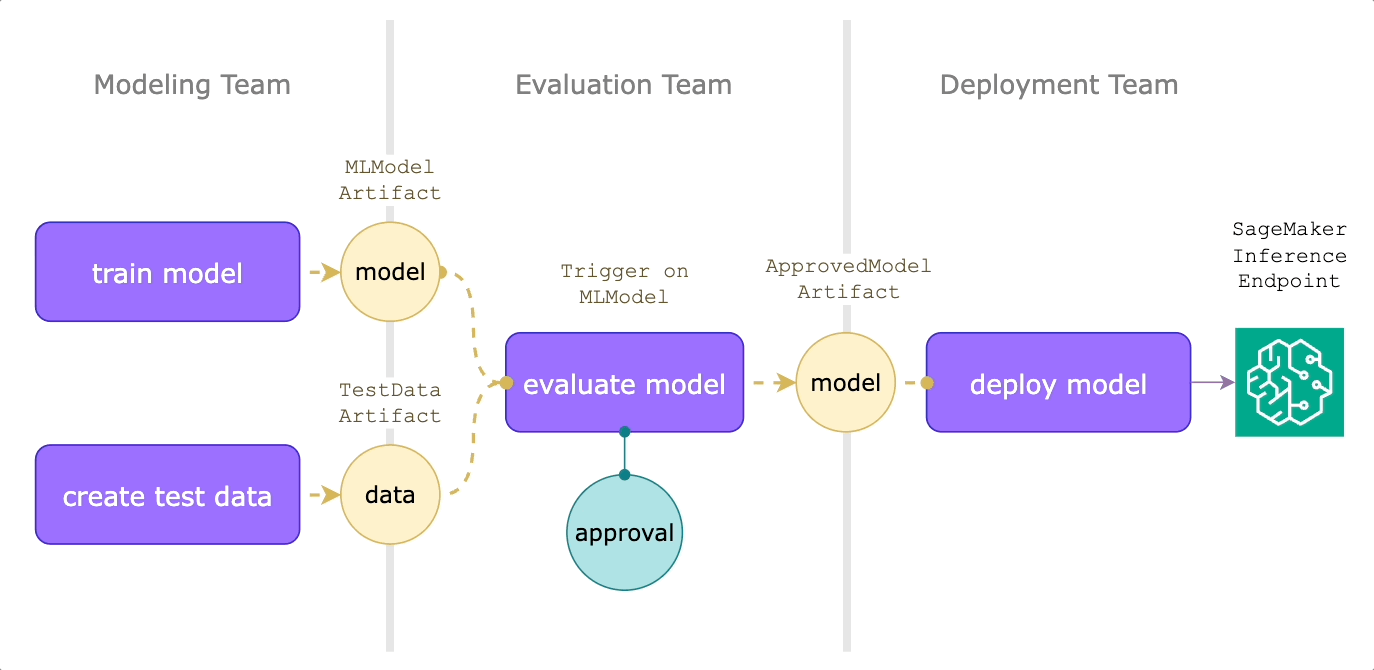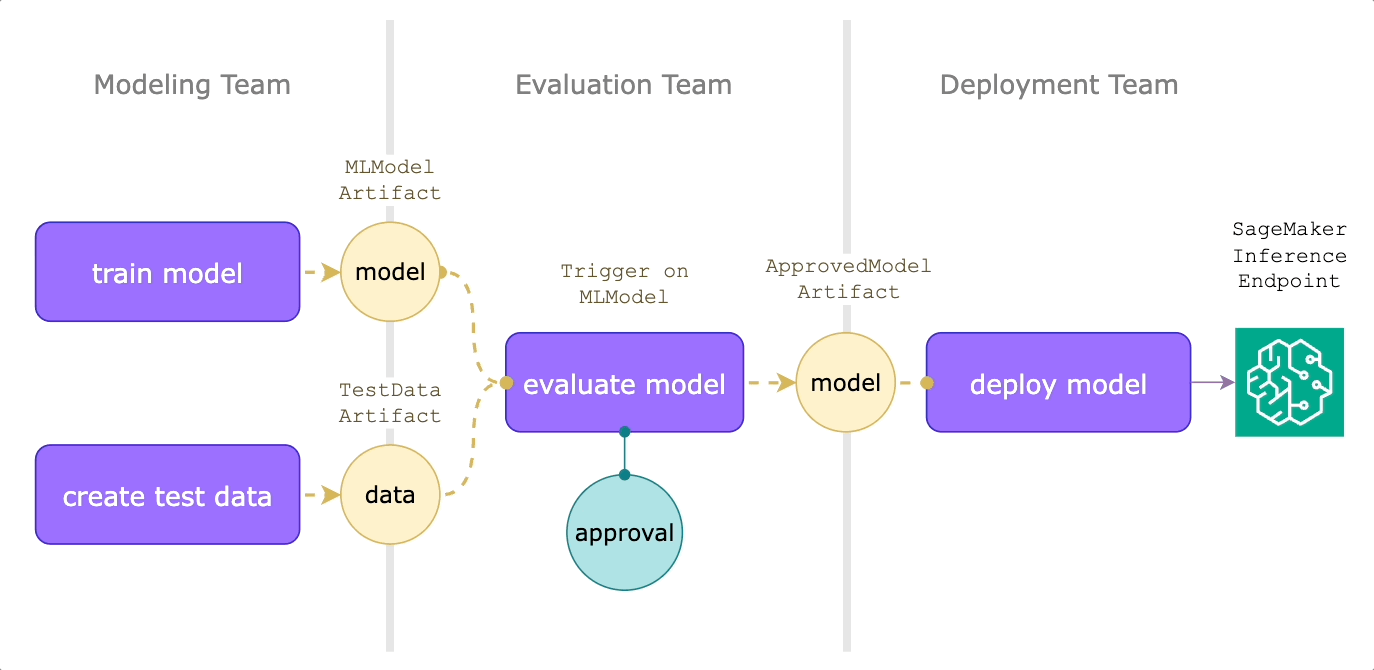
Model deployment on human approval
Reactive workflows can also improve the model deployment process. Suppose you have modeling, evaluation, and deployment teams. Every time a new model is published, we want it to go through an expert review process before it’s deployed to production.

The modeling team might create an evaluation workflow like this:
Let’s walk through what’s happening here:
- This workflow uses `OnArtifact` to define when the `model_evaluation_and_approval` launchplan should run via the `trigger_on` argument.
- Then, it can determine what inputs to provide via the `MLModel.query()` and `TestDataset.query()`.
- The launchplan then calls `predict_and_evaluate`, which produces a `FlyteDirectory` containing the evaluation report, which will be rendered as a Flyte Deck.
- The `approve` node makes sure that the deployment team can audit the Flyte Deck within 24 hours for deployment to production.
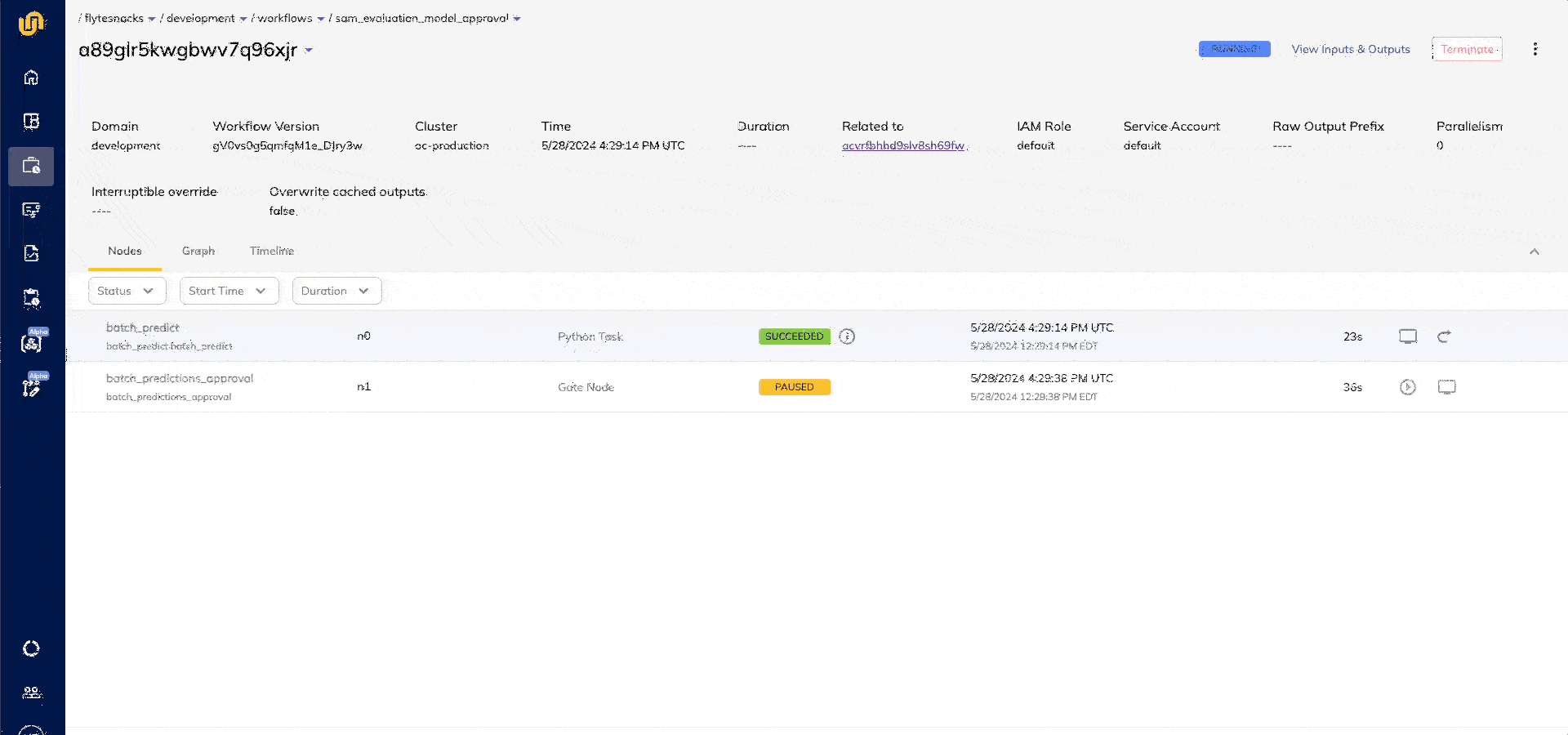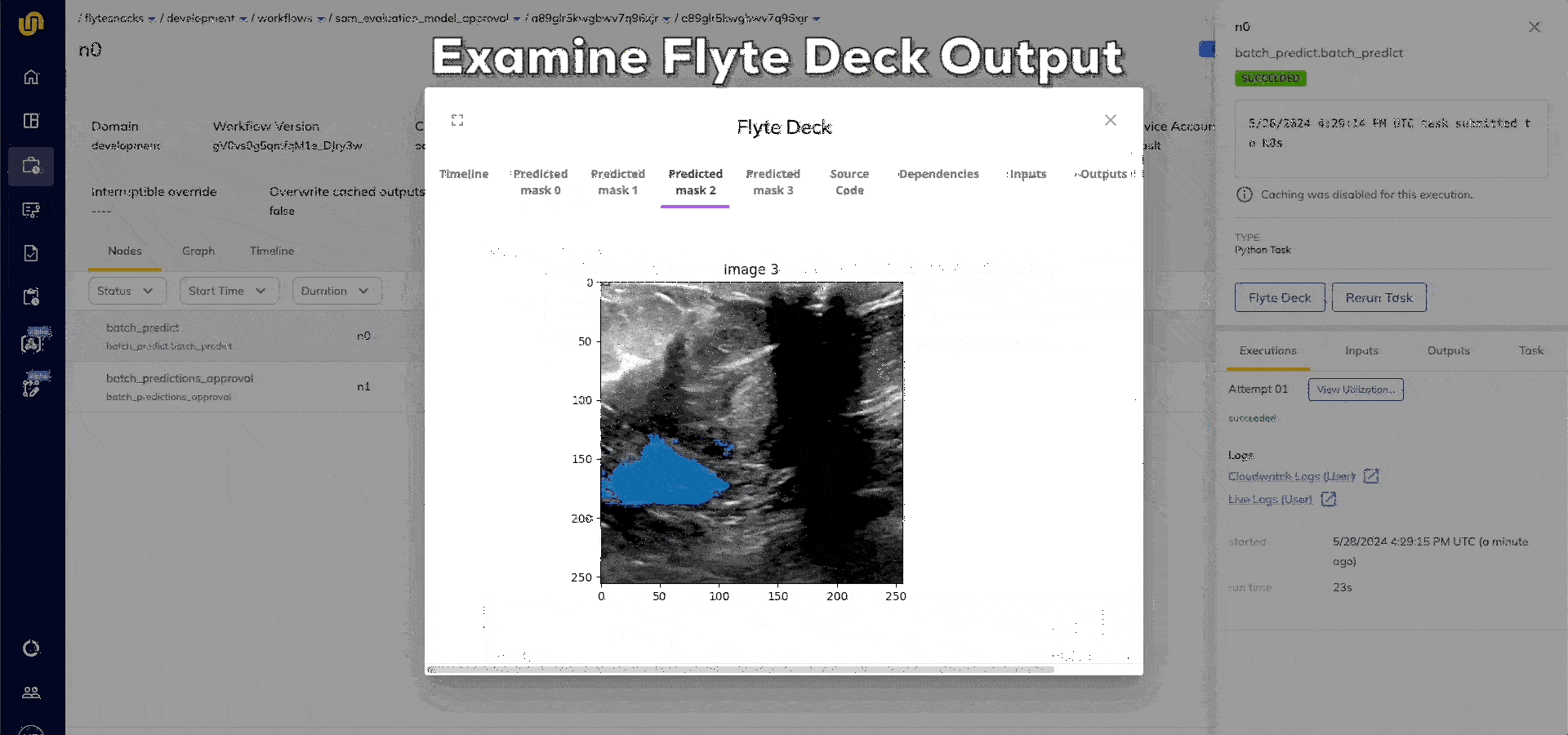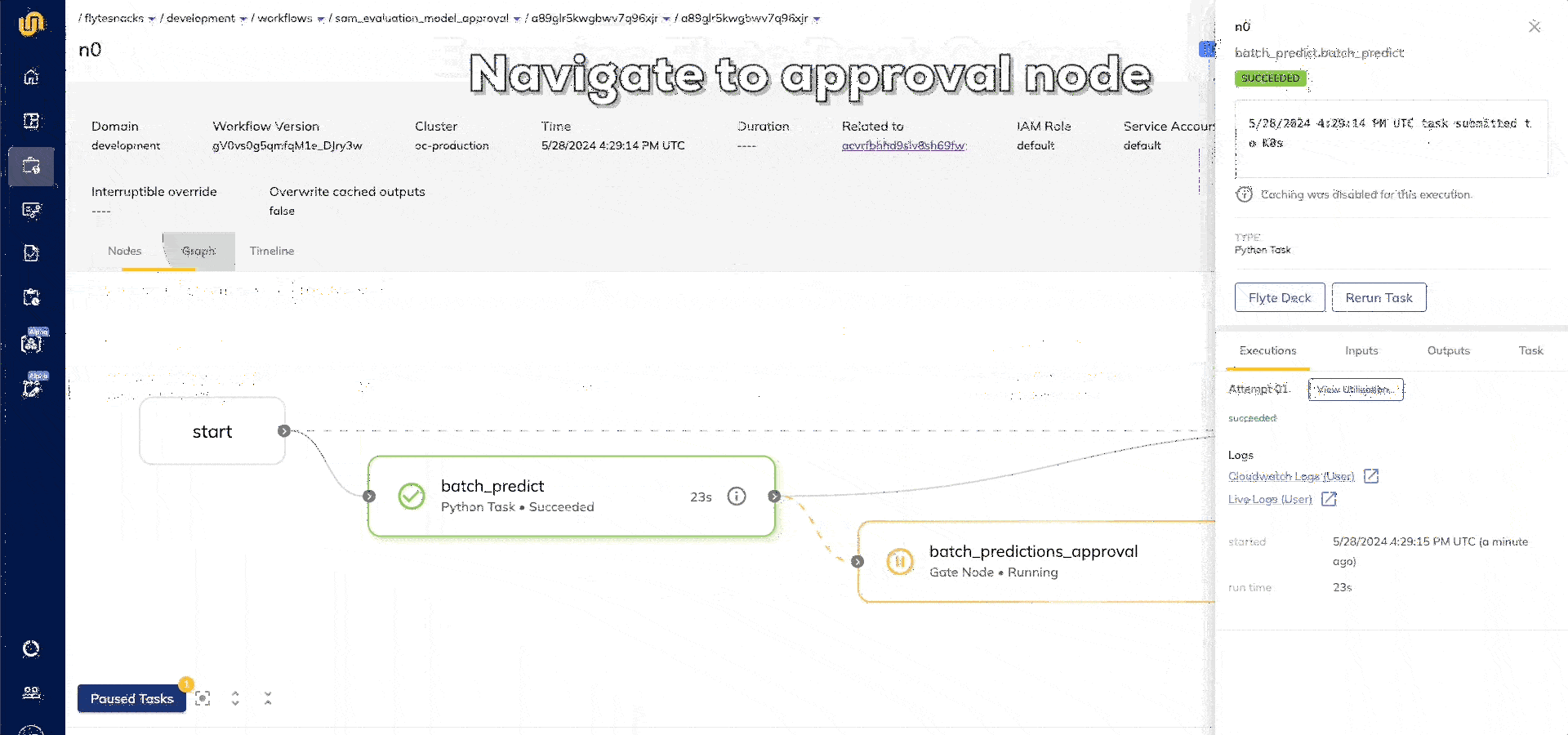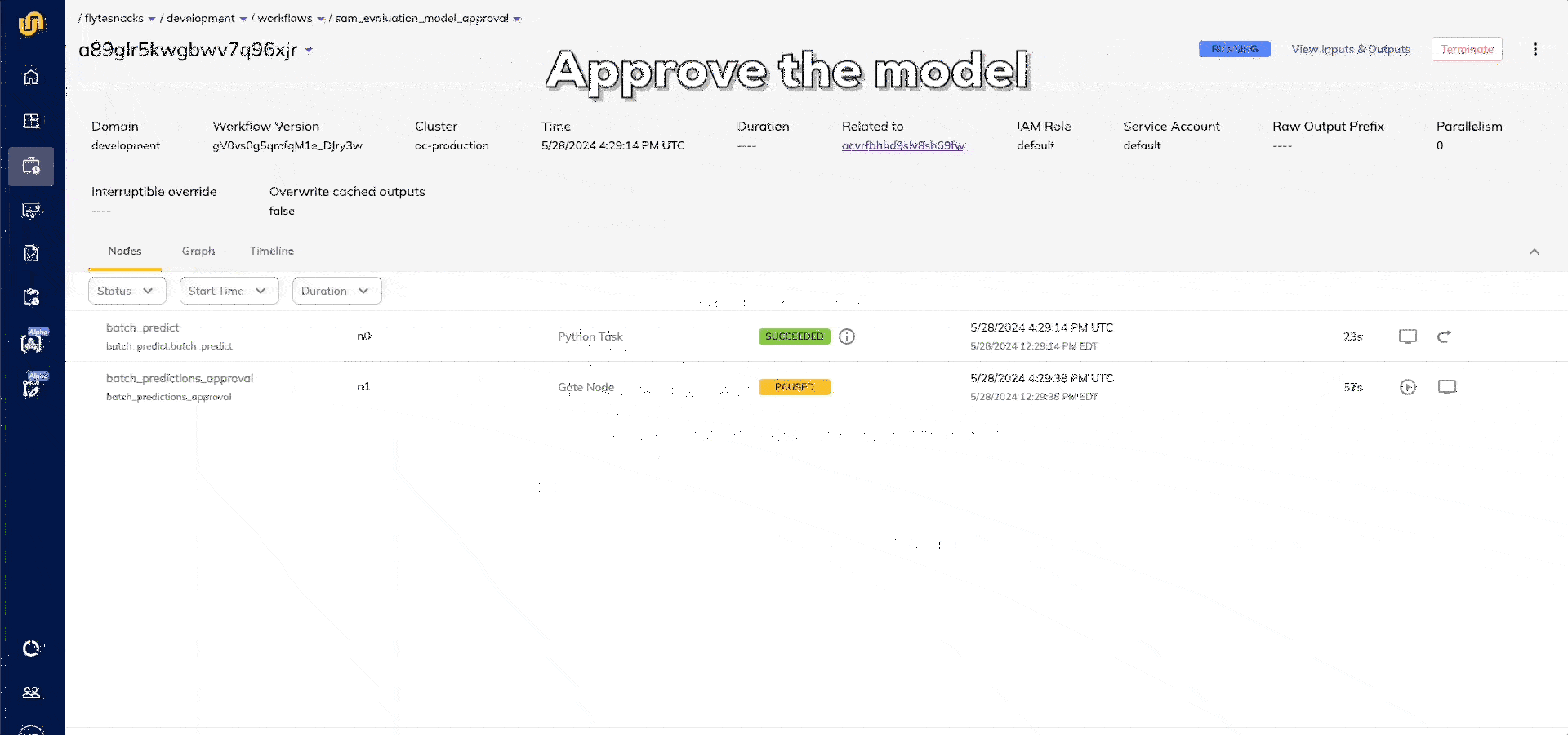
When a model is approved, the deployment team can then react to this event with another triggered launch plan. Assume that they’re using SageMaker for hosting model endpoints, we can use Flyte’s SageMaker inference agent:
The `deploy_on_approval` launch plan uses `OnArtifact` to kick off the `deploy_model workflow`, which uses `ApprovedMLModel.query()` to automatically pass in the approved model at runtime. This will then create a SageMaker inference endpoint, the specs of which are output as a json string.
Conclusion: Deeper insights into state and lineage
At the end of the day, Artifacts unlocks deeper data-awareness in Union, showing you how data flows through the different parts of the AI/ML lifecycle. You can easily discover what artifacts exist on the Union console:

For any given artifact, you can see all of the upstream artifacts and workflows that went into producing it, and what workflows consume it to produce downstream artifacts.

On top of Flyte’s strongly coupled workflow abstraction, which you can view as “islands” of compute, you can now build constellations of softly-coupled “archipelagos” of workflows on Union. These workflows are connected together via the datasets and models that serve as the interface between the stages of the AI/ML development lifecycle.
What’s next
We’re excited to see what Union users are going to do with Artifacts, and we’ve already gotten a lot of great feedback for future development. To give you a sense of where we’re going directionally, here are a few high-level areas we’re looking to invest in:
- Easier search, discovery, and navigation of artifacts in the Union UI
- Support external artifacts so that you can upload datasets and models from your local machine or import them from sources like HuggingFace hub.
- Plug model artifacts into any serving system (e.g. SageMaker) as the source of truth
- Introduce data quality tracking as a first-class experience with dataset artifacts and pandera
- Integrate artifacts with accelerated datasets to easily mount artifacts into your task containers that use large static datasets/models/data objects to speed up job startup time.
To learn more about artifacts, check out the Union documentation to get started with artifacts and reactive workflows. Contact the Union team if you’re interested in building end-to-end AI applications!