Machine Learning isn’t cheap. Chiefly, when one massive model or several multiple models are to be built, it eats up your time, money, and effort. Imagine wanting to revert to a previous model artifact if the current model isn’t performing as effectively as the previous model. If you do not have access to the previous model’s results, you would have to go all the way through modifying your parameters, training your models, and estimating the performance. A not-so-easy job, indeed!
This use case is just the tip of an iceberg. There are endless cases where you might want to version your models, cache your results, or backtrack to a specified workflow. All these tenacious jobs fall under the maintainability and reproducibility of machine learning models.
Note: The term workflow is used throughout this blog to indicate any machine learning job.
Unearthing the Necessity
Maintainability and Reproducibility of machine learning models isn’t a walk in the park. It requires a lot of effort to maintain and reproduce a model artifact. In a small company that has just begun its machine learning journey, these orchestration techniques could seem optional. But when deploying models into production where users would actually use your models, here comes the necessity.
- A multi-tenant service is required to host your machine learning models to serve them to multiple users.
- The output needs to be cached to let go of repetitive executions.
- Backtracking to a specified model artifact is required if it performs better than the current executions, highlighting the need for a rich data lineage.
- Executed jobs need to be shared with your team members to avoid executing them again and again. Moreover, the instantiated jobs might also need to be shared — as an example, consider a case where you’d like to share a feature engineering algorithm with your team.
- Pipelines of code or infrastructure need to be scaled at some point in time.
These points highlight the significance of having a sophisticated platform that could seamlessly integrate with and enhance your bare machine learning models.
How Hard Is It?
So, how hard is it to build such a platform?
We believe the following are five fundamental issues that will pop up when models have been pushed to production:
- The model must be containerized, without which maintainability is genuinely complex.
- Machine learning workflows need to be tracked, no matter how many.
- Switching back and forth between the workflows is quintessential; concurrency amongst them has to be ensured.
- The iterative development of models needs to be supported.
- The models have to be constantly monitored, and when there’s a failure, an appropriate set of actions has to be decided upon without disrupting the machine learning jobs.
At first glance, they do not seem easy to implement, and in fact, they aren’t. There’s a whole lot of logic that needs to be taken care of.
What if there were a platform to transform your company from dealing with bare machine learning models to creating concurrent and maintainable workflows with a hefty dose of orchestration?
The Solution
Flyte could be your solution. It handles the majority of the problems highlighted earlier. Here’s what Flyte offers:
- Flyte is built on top of Kubernetes, thus ensuring maintainability, scalability, and portability.
- Flyte caches the outputs for every job you trigger. For local deployments, we use Minio. You can use S3, GCS, etc., for remote deployments. If the job has been run before with the same set of inputs, Flyte picks up the cached outputs regardless of who executed them.
- Every entity is captured as a new version. And the smaller entities (or tasks as Flyte calls them) within a machine learning workflow can be shared with other workflows, eliminating the redundancy across your teams. Additionally, workflows (larger entities) can also be shared.
- Flyte utilizes directed acyclic graphs (DAGs) to replicate the workflow, which helps confirm the relationship between the workflow, and the inputs and outputs.
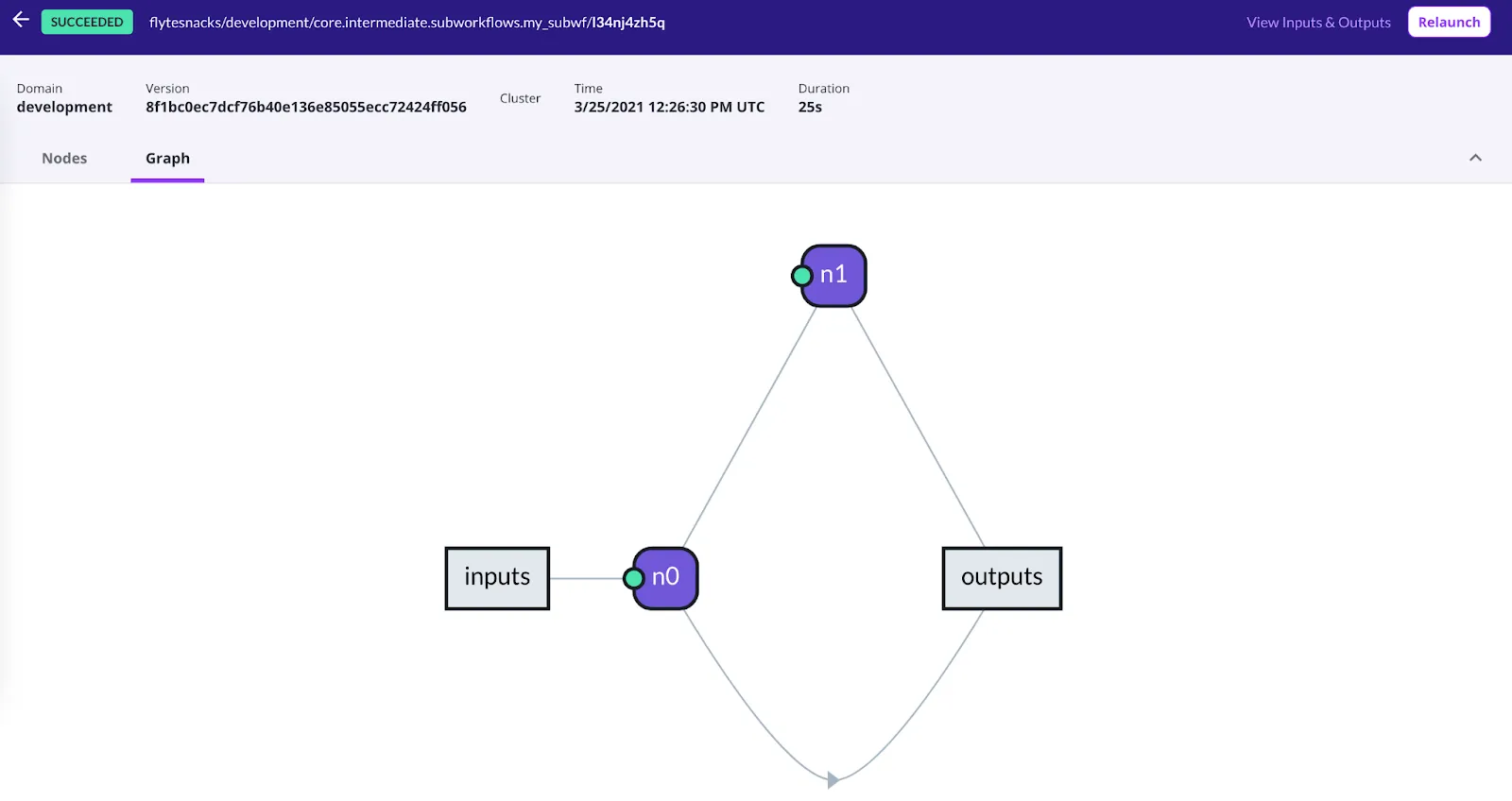
- Logs are captured for every workflow to help backtrack to the error source.
- Flyte supports containerization and multi-tenant scheduling, which lead to isolation and thus help with fault tolerance to a great extent.
- Every workflow is assigned a version. You can roll back to a previous workflow if needed.
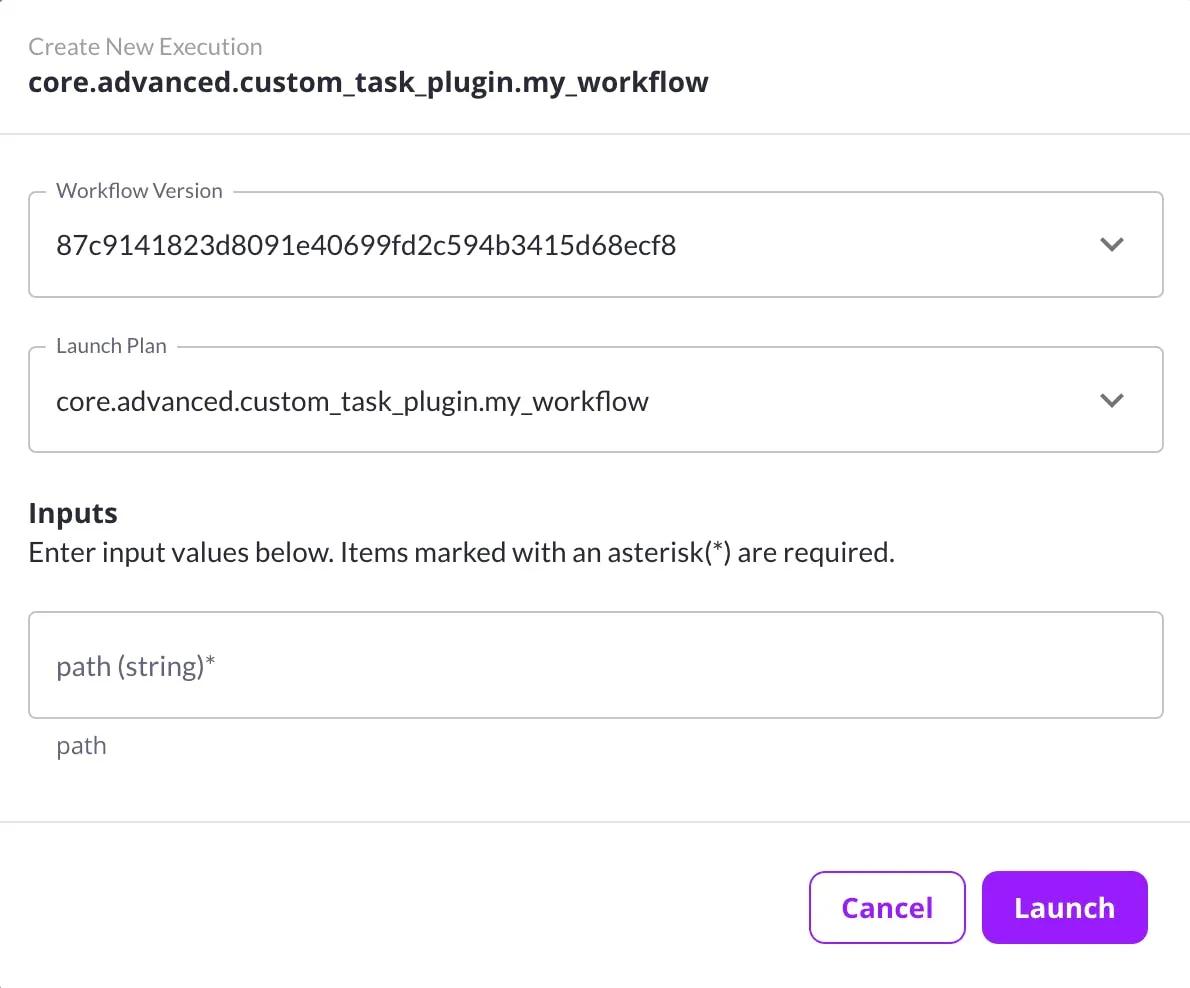
Flyte provides an intuitive User Interface (UI) capturing all the features mentioned above. You can ascertain the workflows that others have executed, launch the jobs with a single click, compare your training workflow results, etc.
Check Us Out!
Ensuring your machine learning models are maintainable and reproducible is essential to enhance team productivity. Integrating it into pipelines is problematic, given the absence of a platform that handles such jobs.
Flyte helps accelerate models to production. It handles most of the maintenance, from the creation of pipelines to orchestration. In addition to machine learning, Flyte is extensively used for data processing.
Flyte has been battle-tested at Lyft, Spotify, Freenome, and others, and is an incubating project at LF AI & Data.
We invite you to check out Flyte at flyte.org and join our community on Google Groups.
To start using Flyte, you can refer to the documentation.