In the fast-paced world of machine learning, data scientists and researchers are constantly battling infrastructure challenges that slow down innovation and drain organizational resources. Traditional notebook-based development has become a productivity bottleneck, burdened by complex, inefficient, and insecure practices that create more friction than flow.
Union’s AI platform enables data science teams to access powerful computational resources without wrestling with manual VM configurations, unreliable experimentation, or excessive cloud costs. Our platform makes prototype development as simple as running a code cell, regardless of which notebook environment you prefer, empowering fast experimentation and reduced time to value.
Pain points of notebooks-based AI prototyping:
The current notebook development landscape is fraught with critical pain points that hold back even the most talented teams:
- Infrastructure management becomes a full-time job, with engineers constantly juggling manual configurations
- Security risks lurk in decentralized data access and inconsistent environment management
- Cost inefficiencies mount as development and production infrastructures are unnecessarily duplicated
- Collaboration suffers as results remain locked in siloed, hard-to-share environments
- Computational scaling becomes a logistical nightmare, especially when GPU resources are required
Union isn't just another tool—it's a comprehensive solution that transforms how machine learning teams develop, prototype, and deploy. By abstracting away the complexity of code deployment, providing seamless compute access, and maintaining rigorous security standards, Union empowers data scientists to do what they do best: innovate.
Here's how Union delivers unprecedented value:
Unparalleled Computational Flexibility
Find the example notebook used in this section here
With Union, your data scientists can break free from the constraints of local machine capabilities. Whether you're working on a modest laptop or need massive GPU processing power, Union provides instant access to scalable computational resources.
To get started, you need to define a UnionRemote object:
This is the “connection” between your Notebook environment and the Union Serverless platform, which gives you access to high performance, scale, and efficiency.
Union’s ImageSpec helps teams guarantee consistent environment configuration from development to production by capturing the expected packages and versions the container image should use. Union’s ImageBuilder service abstracts away a complete container infrastructure to securely build, store, and retrieve container images on demand. In this way, every time a Notebook runs, regardless of the particularities of the underlying platform, the code will use the expected environment the model author intended.
Additionally, you can specify compute resource requirements -including GPU accelerators- at the task or workflow level, extending configuration consistency to the infrastructure layer:
This means running complex machine learning models, processing large datasets, and conducting intensive research that can be efficiently served and operationalized, is as simple as running a code cell.
Cost Optimization Reimagined
Traditional cloud computing solutions force teams into expensive, always-on infrastructure models. Union flips this script with its ephemeral compute approach. Resources spin up instantaneously when needed and scale down to zero when idle, dramatically reducing computational costs.
Using Union Actors, you can define a long-running container instance reused for multiple executions, dramatically reducing the time and cost of cold-starts.
To configure Actors, you just need to declare an ActorEnvironment:
Then you can use the same environment for multiple tasks in the same workflow and tasks across workflow definitions:
These features, combined with a pay-per-use pricing model, and the Cost Allocation dashboard that lets you explore and track costs down to the execution level, enable teams to slash infrastructure expenses significantly, compared to traditional platforms that require long-running, expensive clusters.
Security Without Compromise
Data security is no longer a trade-off against development speed. The Union AI platform is SOC2 Type II certified, which means it maintains strict access controls to keep data within your cloud environment, mitigating the security risks associated with manual data configuration and decentralized access.
Also, Union’s core execution engine captures user identity to federate secure access to the data you keep in your cloud, enabling you to quickly and securely access data and prototype in local or remote notebook environments.
Development Workflow Freedom
Forget being locked into specific development environments. Union supports virtually any notebook platform—Google Colab, Jupyter, Databricks, Replit, and beyond.

This means your team can continue using their preferred tools while gaining access to powerful, scalable compute capabilities, resulting in a frictionless development experience that meets developers where they are.
Collaboration and Reproducibility
Union breaks down the silos that traditionally fragment machine learning workflows. By providing a consistent, shareable infrastructure, teams can easily reproduce experiments, share results, and collaborate more effectively. No more "it works on my machine" scenarios or complex environment replication challenges.
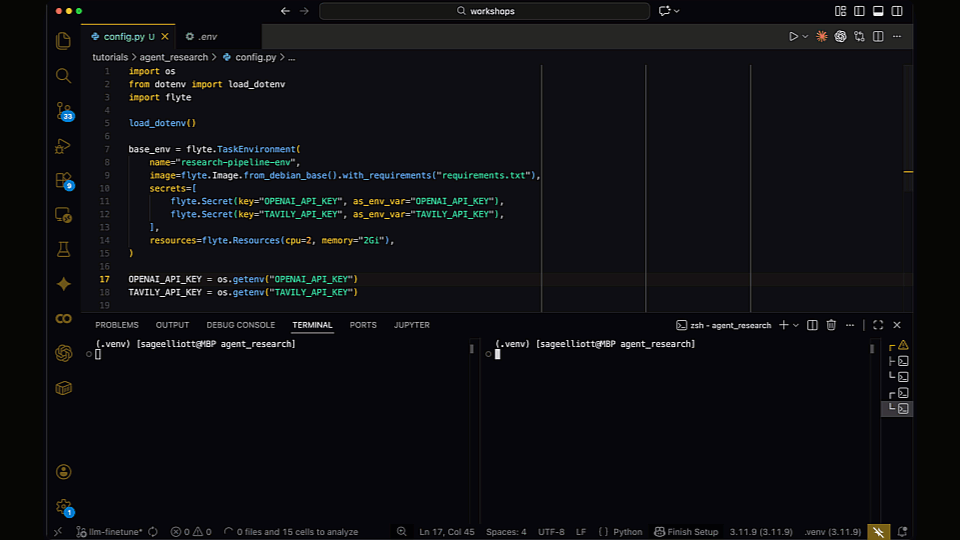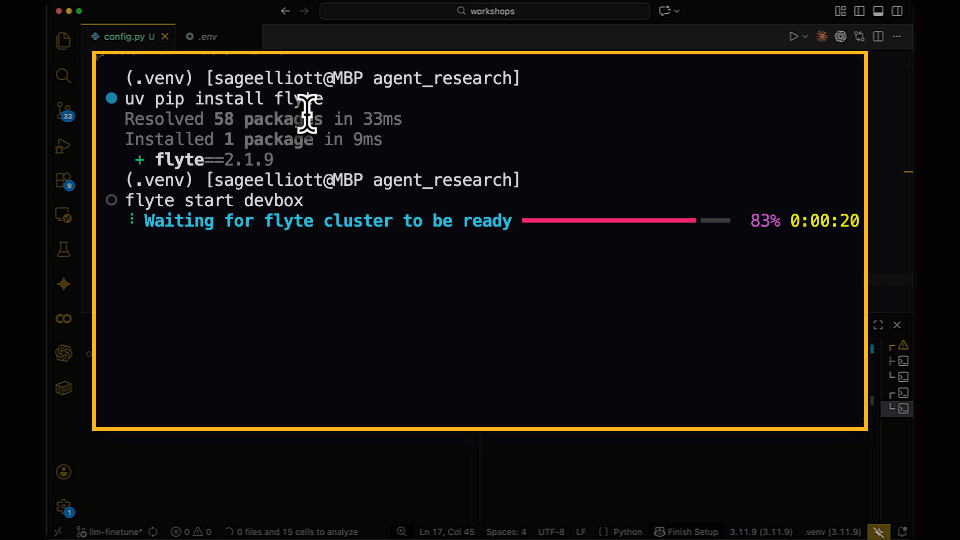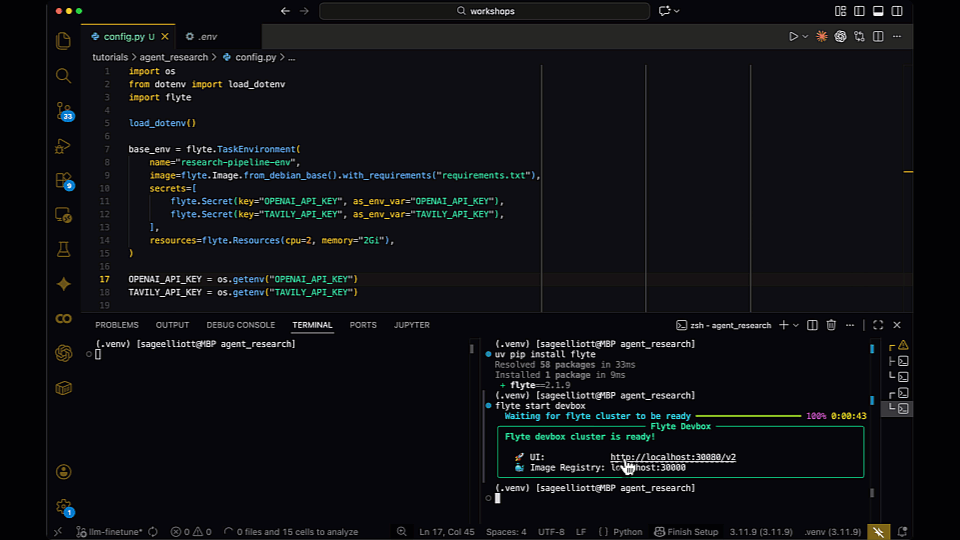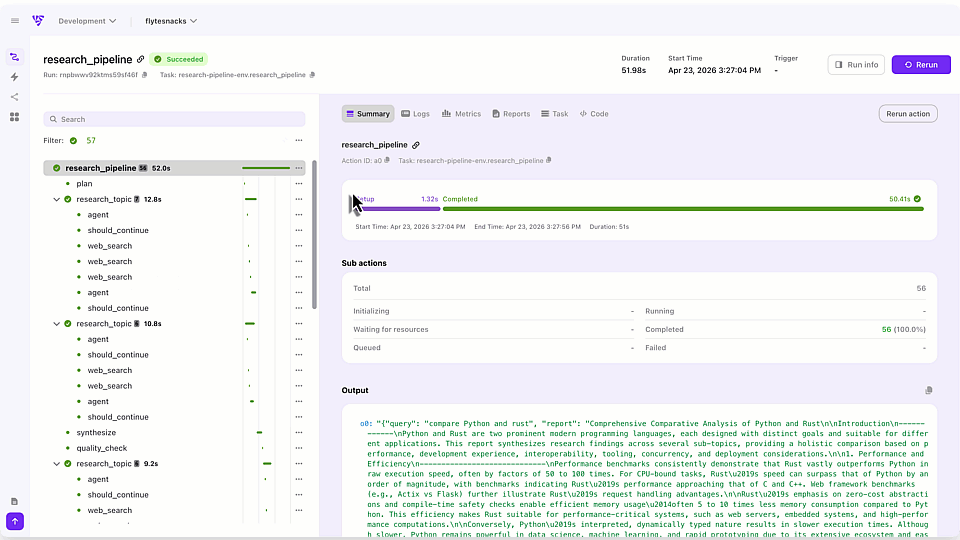
Union’s execution engine uses versioning to keep track of the execution inputs, outputs and any additional metadata. This means that results are no longer confined to a model developer laptop but are reproducible and easily shareable between teams.

Conclusion
Notebooks are an essential component of the toolkit for the large majority of data scientists and ML engineers when it comes to exploring a dataset and interacting with it for experimentation. Moving code developed in Notebooks to a production-grade application is not available out-of-the-box, and usually requires interacting with multiple external systems, while dealing with the hidden states and unreliable execution order Notebooks have. The Union platform bridges the gap between Notebooks and reproducible experimentation that modern ML systems require.
Sign up for Union Serverless free tier here and experience the power of unmatched scalability, directly from your Notebook!