When to manipulate the input prompt and when to roll up your sleeves and update parameter weights.
Chances are you’ve already interacted in some way with a Large Language Model (LLM): either through a hosted interface like ChatGPT, HuggingChat and Bard, or — for the hackers out there — via some home-grown UI or terminal that you can run on your laptop using tools like Llama.cpp and Dalai. Whatever the case may be, it’s clear that what we call “prompt engineering” is more art than science.
Fundamentally, prompt engineering is about getting the model to do what you want at inference time by providing enough context, instruction and examples without changing the underlying weights. fine-tuning, on the other hand, is about doing the same thing, but by directly updating the model parameters using a dataset that captures the distribution of tasks you want it to accomplish.
In this post, I want to describe prompt engineering and fine-tuning in more detail, give you a practical sense of how they are different, and provide you with a few heuristics that will help you begin your fine-tuning journey.
Prompt Engineering: the art of coaxing the model’s latent space to get what you want
Essentially, prompt engineering goes like this: Say you have a task you want to accomplish. For example, you want to write a blog post about LLM fine-tuning (you see where I’m going here 🙃). In the spirit of open source, I’ll use HuggingChat as my writing assistant. This system is based on a refined version of Llama, an open-source model series first released by Meta (though it has a non-commercial use license). The full conversation can be found here.
First, you might write a prompt like this:

To which it responds:

Okay, not too bad! The problem is, the link it gave me is actually “hallucinated” – the technical term in the field to describe confidently provided facts and citations that are completely false. The creation of pseudo-citations has been documented widely among GPT users and is a topic of active research in the ML community. I actually want it only to produce a short, few-bullet point outline, so I ask it:

To which it replies:

It decided to give me just two bullet points and it starts to ramble with some nonsensical phrases like “electri net” and “hub modi fiers”... Clearly, I’m not a very good prompt engineer, or maybe I can blame it on the model!
In any case, you get the idea: In a very hand-wavy sense 👋, prompt engineering is about coaxing the model into a region of its latent space by manipulating the input prompt such that the probability distribution of the next-tokens that it predicts matches your intent. In this case, my intent in using this tool is to give me a high-level outline for this blog post so I can get ideas on how to structure it.
There are many ways of doing this, such as providing examples of what kinds of outputs you want, instructing it to write “in the style of” certain authors, using chain-of-thought reasoning, exposing the model to use external tools, and more. In fact, much has already been written about how to optimize prompts to use language models efficiently, including guides/courses produced by DairAI, Cohere and Coursera. Now let’s contrast this activity with fine-tuning.
Fine-tuning: Updating model parameters
Fine-tuning has been around as long as the idea of pre-training models, even before transformers, attention and language models as we know them today. Fine-tuning is the act of further specializing a model that has typically been trained on a broader data distribution by updating the model’s parameters in some way.
This post won’t dive too deep into the technical side of fine-tuning, mainly because there are already some fantastic resources out there, like this post from Sebastian Raschka, or this one by Chip Huyen. But at a high level, we can think of fine-tuning along two dimensions: what kind of dataset you’re using and how you decide to update the parameters.
The structure of the dataset informs what the model learns
I want to pause here just to emphasize this point: Models are representations of data. During the training process, models find a way of compressing and representing data to best capture the patterns in the data itself. The structure of the dataset determines what kinds of capabilities you explicitly want to imbue the model with. Broadly speaking, fine-tuning entails at least three kinds of datasetst:
{{tuning-dataset="/blog-component-assets"}}.
How you update the parameters determines cost and training time efficiency
As base models become larger and larger, the efficiency of training frameworks for fine-tuning models becomes more critical. This trend may or may not continue based on fundamental innovations in architectures, optimization techniques and hardware, but it seems that today you’re looking at 1 billion to 175+ billion parameter models, and only those at the lower end of this range will be accessible for smaller companies and individuals to fine-tune.
That said, if you can get your hands on one of the dataset types that I mentioned above and a GPU that can fit your base model of choice, you can try updating your model weights through the three conventional approaches described in more detail in this post:
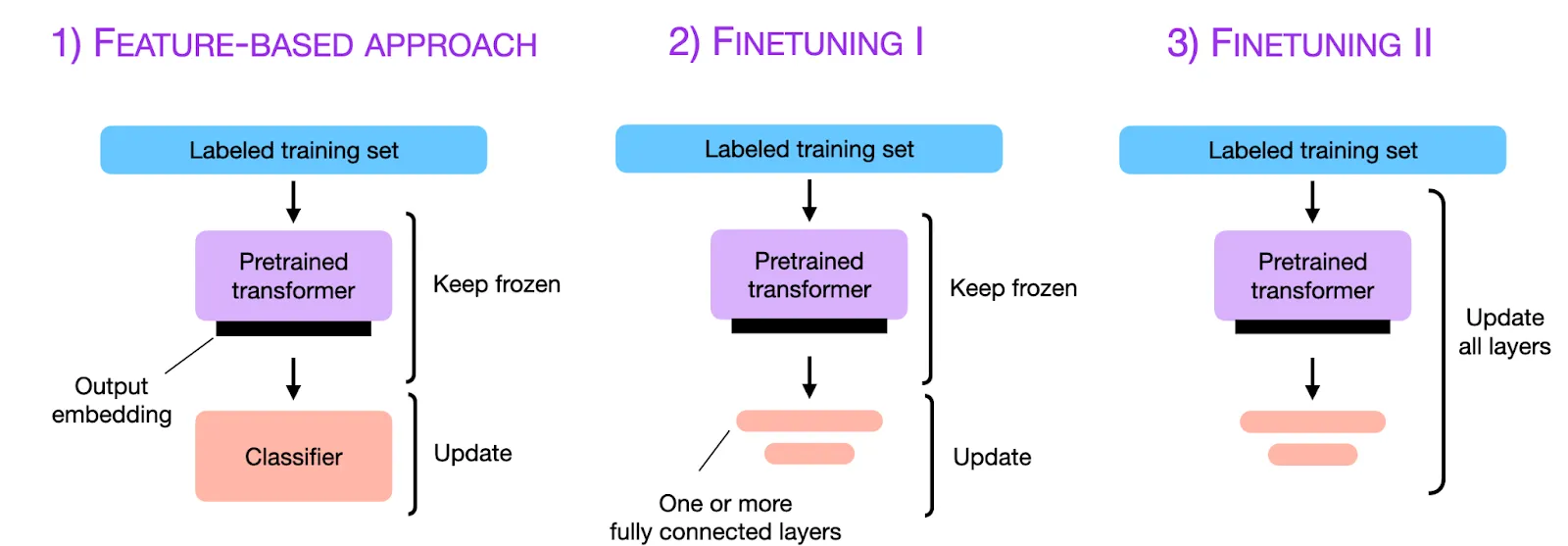
Moving from left to right means that you trade off higher performance for lower parameter efficiency. Using your base model’s outputs simply as a latent representation of the raw data means that you can use any off-the-shelf classifier or regressor (think scikit-learn models or XGBoost), which will be the trainable set of parameters in the system. On the other hand, updating all the layers in the transformer will require much more memory and compute power, but it will allow your model to perform better than a low-capacity model or shallow network.
Parameter-efficient fine-tuning reduces the number of trainable parameters
Parameter-efficient fine-tuning (PEFT) refers to a category of techniques similar to “Finetuning I,” where only the last few layers of the network are trainable and the rest are frozen.
One technique that straddles the line between prompt engineering and fine tuning is called “prompt tuning”, which uses “soft prompts” that are generated by a small set of learnable parameters. This is in contrast to prompt engineering, which uses manually-provided “hard prompts”. In the prompt-tuning paradigm, instead of manipulating the input tokens, we use a fixed set of prompts P for each task (e.g. translation or sentiment analysis) and we use a small set of prompt weights WP to manipulate the actual input embedding values that we feed into the base model so as to minimize the cross entropy loss associated with the prompt responses in the dataset.
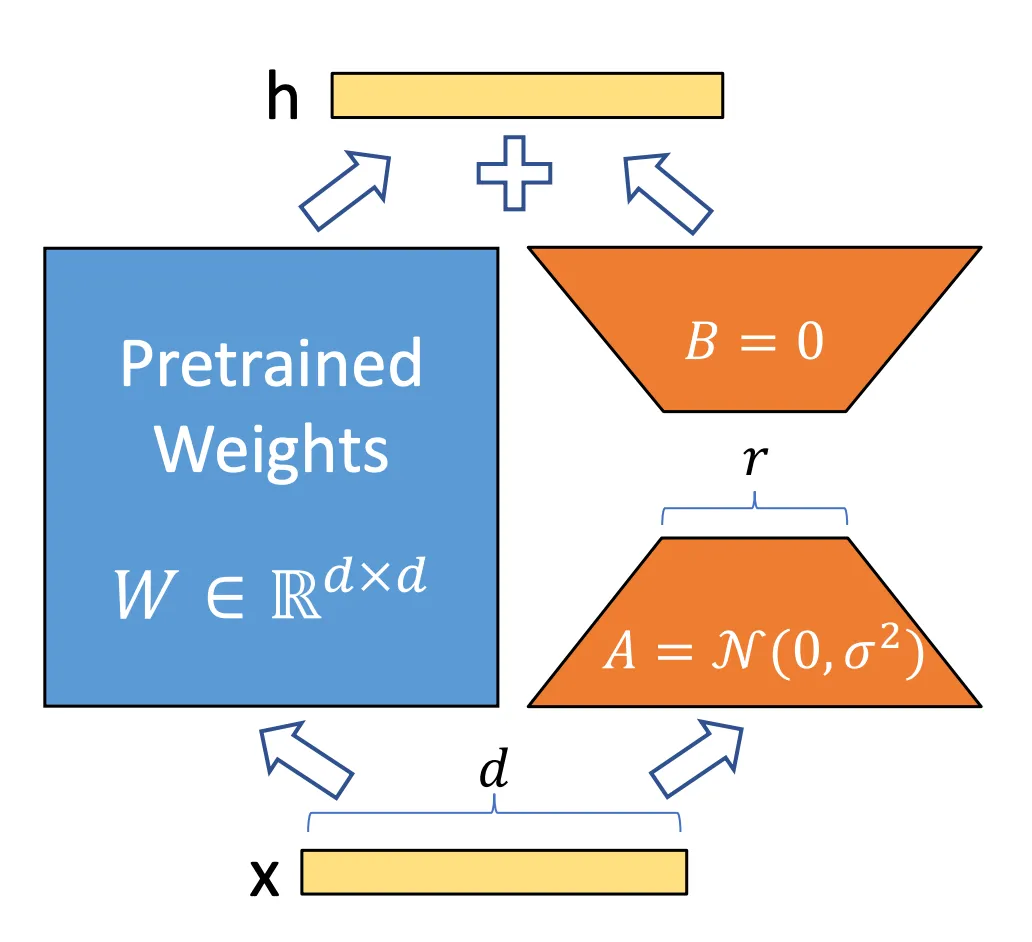
Another example of a more recent PEFT technique is Low Rank Adaptation, or LoRA, which is a powerful method that takes advantage of the fact that a single update step produces a new set of weights W’, which is the original model weights W plus the gradient updates ∆W:
W’ = W + ∆W
Glossing over many of the details, the key insight of LoRA is that ∆W can be replaced by a set of lower dimensional weights A and B: as long as A x B produces a matrix with the same dimensionality as W, we can reduce the number of trainable parameters by several orders of magnitude.
We want more efficiency!
But what if we want more efficiency? There are other tricks we can use to make fine-tuning (and training in general) more efficient. Here, I wanted to highlight two such techniques for improving training efficiency: quantization and zero-redundancy optimization. Going in depth into these topics would warrant another set of posts, but let’s briefly cover each of them at a high level.
Quantization reduces memory utilization
Quantization is the process of reducing the precision of numerical data so it consumes less memory and increases processing speed. However, lower precision leads to the drawback of lower accuracy as less information is being stored per layer. This doesn’t just apply to neural networks: if you’re a data scientist or ML engineer who has used Numpy, Pandas, or any other numerical library, you’ve probably encountered `float64`, `float32` and `float16` data types. The numbers 64, 32 and 16, respectively, indicate how many bits are used to represent, in this case, floating point numbers.
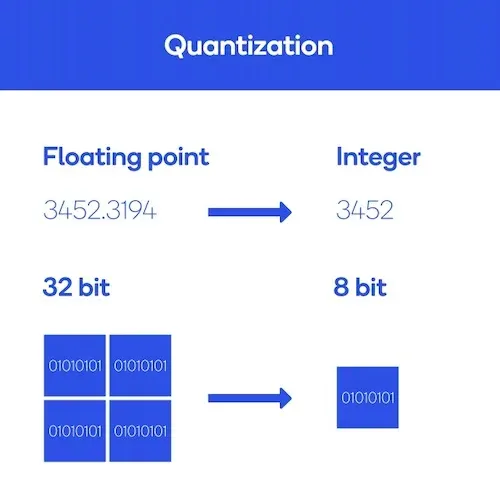
In deep learning frameworks like PyTorch, TensorFlow and Jax, it’s common to provide utilities to do mixed-precision training: this allows the framework to automatically cast the weights, biases, activations, and gradients to lower floating point precision (e.g. `float16`) when appropriate, and then cast them to higher precision representations (e.g. `float32`) where numerical stability matters, for instance in gradient accumulation or loss scaling. One library that may be of interest to fine-tuners is the bitsandbytes library, which uses 8-bit optimizers to significantly reduce the memory footprint during model training.
Zero-redundancy optimization shards and offloads model state
A few years ago, the only sort of data parallelism that you could easily leverage with deep learning libraries consumed a lot of GPU memory. Essentially, if you have a machine with four GPUs, you could replicate the model four times, and if you could train a batch size of 8 on each GPU, you would obtain an effective batch size of 32.
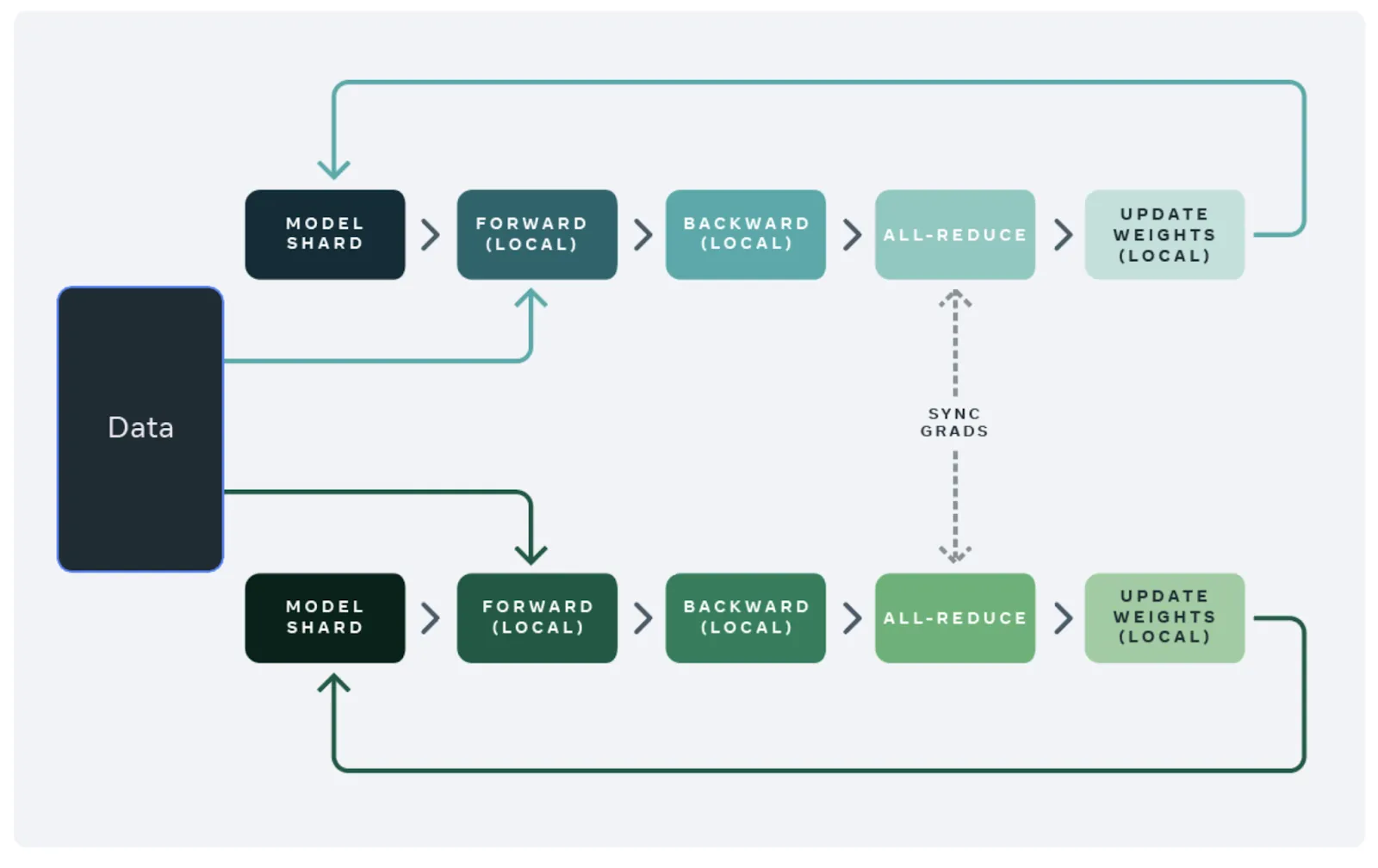
The ZeRO paper, which is available via DeepSpeed and Pytorch’s FSDP implementation, enables you to shard the optimizer state, gradients, and parameters across the available GPUs and CPUs in the training system. This is done in a layer-wise fashion, such that only the model state required for a specific local forward/backward pass is replicated across GPUs. For example, if you’re training a neural net with three layers, the ZeRO protocol replicates the model state required for the forward pass of the first layer, freeing up memory once the activations are obtained. This is then done in the forward passes for layers two and three. Finally, this process is applied to the backward passes, resulting in updates to the parameters of the model.
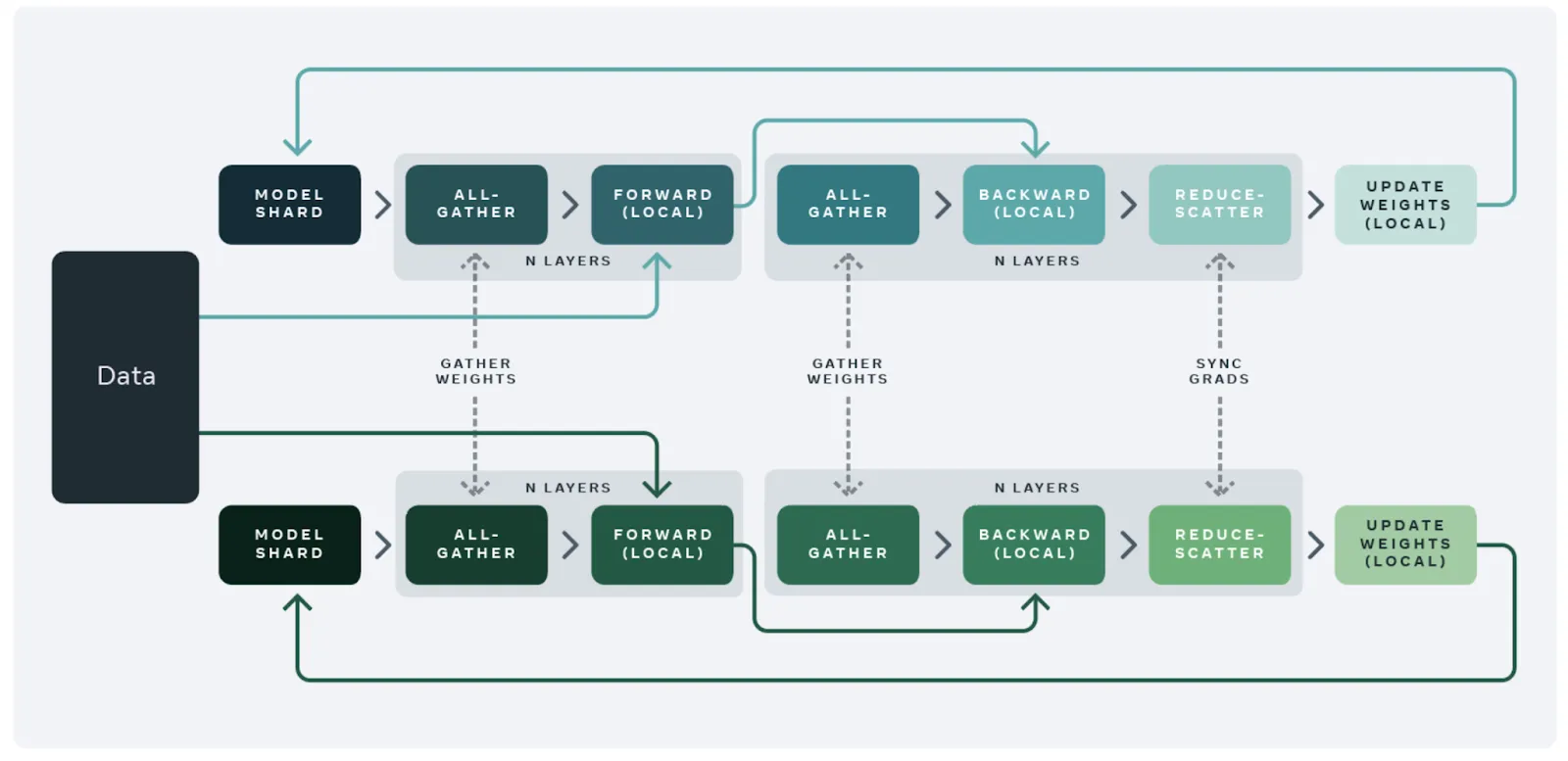
The ZeRO framework also allows for offloading of model states to CPU or NVMe where appropriate, which further reduces GPU memory consumption and improves training speed.
When do I prompt engineer, and when do I fine-tune?
We’re still in the early days of fairly accessible LLM fine-tuning at the scale of billions of parameters. In the last part of this post, I’ll leave you with a few heuristics that may help you decide whether to prompt engineer an existing foundation LLM or embark in fine-tuning efforts.
Firstly, it’s important to understand the requirements and scope of your use case so that you can match it with the capabilities of the LLM that you have access to. For example, say you want to build a customer service Q&A system for your software platform. Practically speaking, fine-tuning is a costly endeavor, and using off-the-shelf LLMs via APIs – like those offered by OpenAI, Cohere and Anthropic – would make sense to test first. Here are a few things to consider:
- Has the LLM been trained on your data or data like it? In our software platform Q&A example, you’d consider whether the code and documentation is open source. If so, it’s fair to assume that the LLMs backing these APIs have been trained on those tokens. This means that they can likely be prompt engineerd to answer questions and even produce code that’s relevant to your problem.
- Do you or does your organization have ML engineering and infrastructure expertise? This may be less of a question as the barrier to fine-tuning is lowered with low- or no-code solutions. But for now, it takes quite a bit of knowledge and know-how to fine-tune LLMs at all, let alone do it in a cost-effective manner. If you don’t have the expertise or budget to fine-tune, you may be better off prompt engineering, although this can also be costly.
- How novel is your task? There’s probably plenty of data out there covering the distribution of text relating to “customer service Q&A,” but what if your task is unique or otherwise not represented well on the public web? It’s hard to imagine an LLM today that can be used in a medical or therapeutic use case that covers “medically valid responses and good bedside manner” because that data is scarce. In such a case, it may be worth it to fine-tune.
As others have pointed out, I think we’re experiencing the StableDiffusion moment for NLP, when people can train and do inference on LLMs with consumer hardware.
To summarize my thoughts on fine-tuning, one way I like to think about it is this: Foundation models provide a great prior for plausible-sounding text generation, and prompt engineering can go a long way toward generating text that accomplishes a wide range of tasks. However, if the task you want these models to accomplish is outside the training distribution, or your efforts to prompt-engineer an LLM with sophisticated methods like chain-of-thought reasoning don’t yield fruit, it might be time to invest in creating a high-quality dataset to further refine a solid base model.