This is part 3 of a blog series on the need for end-to-end reproducibility in AI development.
The previous posts in this series discussed why AI reproducibility is hard. Modern AI development brings new requirements for managing the way that data, models, infrastructure, and environment configuration all fit together. We also talked about some common best practices for achieving reproducible AI, such as containerization, experiment tracking, data versioning, and workflow orchestration. This post dives into Flyte, the open source container-native AI workflow orchestrator, and shows how teams can leverage this development framework to achieve reproducible workflows while dramatically boosting iteration velocity.
How Flyte Supports Reproducibility
Flyte was created and open-sourced by the members of Union’s founding team to facilitate rapid iteration in machine learning development, in large part by solving the reproducibility problem. Flyte’s strong typing, versioned entities, data management, containerization, and declarative infrastructure work together to provide reproducibility while accelerating iteration velocity.
Versioned, Containerized Entities
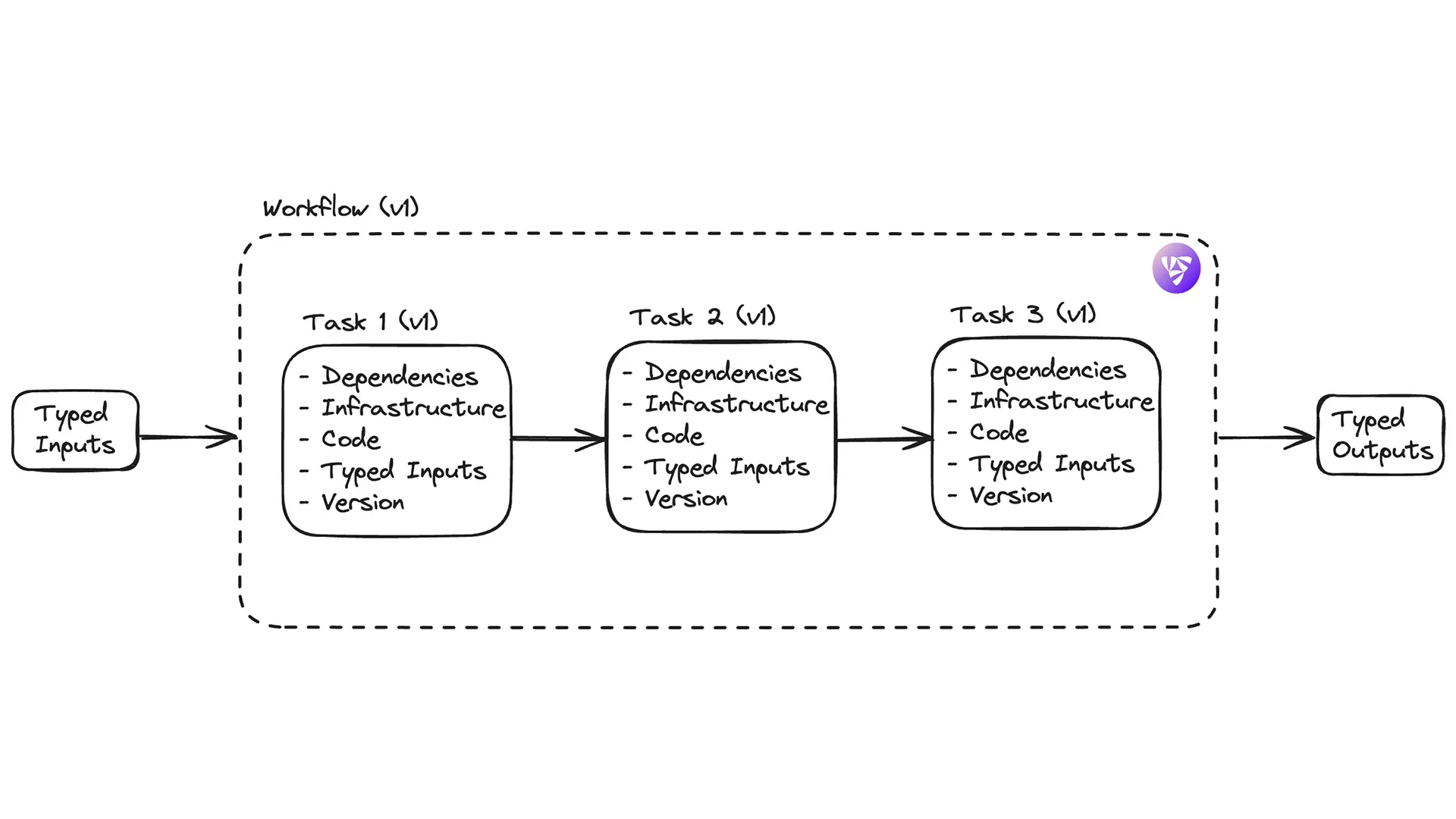
Tasks, Workflows, and Executions are the basic units of orchestration within Flyte. A Task is a Python function extended with a @task decorator. Workflows, which are Python-like functions with a @workflow decorator, call Tasks in the order they are to be executed. Tasks are manifested as containers at execution time and can specify their own distinct dependencies (images) and infrastructure (resource requests). Tasks and Workflows are defined in code and can thus be tightly coupled with version control systems using GitHub Actions.
All Flyte entities are immutable and versioned. When a developer registers changes to a workflow, a new version is automatically created while the original remains available in the system. When a Task or Workflow executes, the execution is assigned a unique identifier which is persisted and visible across the platform. By enforcing mandatory versioning and containerization, Flyte introduces some guardrails on all executions to ensure they are robust to changes in infrastructure and code dependencies.
Strong Typing and Abstracted Data Flow
Flyte requires that all Tasks and Workflows utilize Python type hints to tell the system about the expected variable types that should be passed around as inputs and outputs. This allows the system to provide compile-time validation that can detect errors before expensive compute jobs are performed. Importantly, strong typing also allows the system to abstract the data flow within the context of a workflow. For example, inputs and outputs that look like data tables (i.e. Spark DataFrames and Pandas DataFrames) are automatically offloaded and persisted in an object store using a common interchange format called Arrow, and references to storage locations are persisted and visible. Strongly typed inputs and outputs enable rich data lineage to be stored with each artifact.

Declarative Infrastructure and Configuration Alongside Code Logic
Declarative Infrastructure: Because Task executions are manifested as containers running on Kubernetes, it is possible to tightly couple infrastructure requirements and code logic in the same interface. Flyte allows users to specify compute resources by decorating the Python function that defines the Task logic.
Flyte also offers a native way of requesting specific GPU resources through the Accelerators framework. This is an improvement over raw Kubernetes, which requires explicitly labeling nodes, requiring more hands-on work at the infrastructure layer, and creating a tighter coupling to specific infrastructure environments. With Flyte Accelerators, AI practitioners can work more flexibly and spend less time thinking about infrastructure details. Flyte’s Accelerators supports many GPU types, including MIG-partitioned Nvidia GPUs.
Images in Code: Similarly, Flyte offers a way to specify dependencies in code using ImageSpec, which aids reproducibility by allowing specific image configurations to be persisted alongside code in version control. While containerization typically introduces the overhead of requiring users to build and manage images, ImageSpec mitigates this friction by eliminating the need to define Dockerfiles and manage images outside the context of the workflow code. At registration time, the image is automatically built on the user’s machine, uploaded to the configured container registry, and injected into the container at runtime. The system skips building if the image already exists. This makes it much easier for users to add dependencies as required by their code logic, enabling more autonomy and iteration velocity.
These features work together to ensure that each Task in Flyte has everything it needs to reproduce the same compute operation, including the code logic, environment (with dependencies), infrastructure, and typed inputs.
Native Compute
Because Flyte is cloud and Kubernetes-native, it is not only a workflow orchestrator but also a compute platform. Tasks and Workflows run on Flyte’s native compute resources by default, eliminating the need to monitor and ensure reproducibility across a web of third party compute services. Tasks can directly leverage any Kubernetes operator, including distributed compute frameworks such as Spark, Ray, PyTorch, and Tensorflow simply by supplying the required configuration arguments in the Task decorator. Flyte executes workloads using ephemeral resources, which are tightly coupled to the job being run and torn down after execution. This means that whether a Task is being run for the first time or the 100th time, the same steps are being performed, which supports reproducibility.

Integrated Best of Breed Tooling with Agents
Agents facilitate easy, fast, and resilient access to third party services while maintaining reproducibility and other benefits of orchestration (like caching, failure handling, and error propagation). Agents are long-running, stateless services that enable users to manage the lifecycle of external jobs - for instance, a Spark job running on a Databricks cluster - in a reproducible and fault-tolerant manner. Agents encapsulate the necessary access credentials, configuration, code logic, and artifact inputs which should be sent to the third party service, manage the lifecycle of the job (including managing retries and failures), and form fully-reproducible nodes within any Workflow. Agents are implemented in pure Python and can be run locally, making them easy to develop and use.
How Reproducibility Enhances Developer Experience
Implementing reproducibility outside the context of the workflow orchestrator introduces significant overheads to the development process. Data, models, code, infrastructure, and configuration all must be stored in context across time. Tooling for this - such as DVC for data, MLFlow for models, GitHub for code, Kubernetes for Infrastructure, and an image registry for dependencies - must each be manually configured and separately maintained. These systems also don’t talk to each other in a first class way. Achieving reproducibility here is technically possible, but introduces frictions that can negatively impact developer velocity. We discussed these limitations in detail in the preceding post.
Flyte’s approach is to leverage the orchestrator itself (i.e. control flow through a workflow) to modularize transformations and automate the storage of intermediate artifacts, making it much easier to recreate historical state and actually improve the developer experience. By taking advantage of the unique properties of a reproducible system, Flyte enables several features, like caching, remote debugging, entity sharing, workflow parameterization, and notebook-based development which work together to dramatically accelerate velocity.
Caching
The combination of versioned Tasks, strongly typed inputs and outputs, and storage of intermediate artifacts enables Flyte to provide powerful caching functionality. If Flyte sees the same inputs being consumed by the same Task and cache version as a previous execution, it can simply look up and return the results rather than repeat the computation. In addition to directly reducing compute costs, caching dramatically speeds up debugging cycles by enabling individual tasks within a pipeline to be worked on without re-running the whole workflow. Caching is one of the Two Hard Things in computer science, hard because without such strong guarantees about the inputs and definition of a function, cached values are subject to inaccuracies, which is unacceptable in a machine learning system. Because Flyte caches the output of an immutable transformation that takes an immutable, strongly-typed artifact as input, the system is able to provide strong guarantees on cached result accuracy (as long as the computation is deterministic).
Remote Debugging
Because Flyte knows everything it needs to re-create a Task execution, including strongly typed inputs saved in an object store, code logic, dependencies, and infrastructure, it is possible to re-create any Task’s execution context, re-hydrate the inputs, and attach an interactive debugger such as VS Code in order to develop code within the remote, fully-scaled execution environment. When combined with Flyte’s native Compute Plugins for distributed computation, this feature is invaluable for rapidly debugging issues that only appear when running at scale. For example, users can step through code being remotely executed in a Spark cluster or a multi-GPU training process. FlyteInteractive was contributed to Flyte by the LinkedIn engineering team as a way to more quickly iterate on their LLM training workloads.
Task Sharing and Composability
Since Flyte Tasks comprise typed inputs and outputs, code logic, infrastructure, and configuration, they are entirely modular and can be composed into multiple workflows. This enables specialization and separation of concerns, even within the context of a workflow. This is similar to a microservices architecture, wherein a user can leverage a module based on its documentation and expected input and output formats, without having to think about the code logic in the module. This paradigm supports the creation of “utility” functions that support a wide range of applications. In biomedical imaging, for example, an AI team can create a single task that performs preprocessing (for instance, by filtering out pixels which are not part of the sample being analyzed). This preprocessing step can then be used throughout the organization and independently managed and iterated upon by the team with this specialty.
Workflow Parameterization with Launch Plans
Launch Plans enable users to parameterize Workflow Executions, for example by providing fixed or default inputs, schedules, and notifications. This paradigm supports the development of generic Workflows which can support multiple related use cases. In the consumer app context, a Workflow can be created which distributes coupons to users in a given geographic area. The geo in question can be supplied by a Launch Plan, which enables regional managers to quickly run coupon promotions within their area of concern. ML engineers can then independently optimize the performance of this workflow across all regions. Because all Executions are immutable and versioned, this entire pattern remains reproducible.
Notebook-Based Development
Because all inputs and outputs are persisted, a Data Scientist experimenting in notebooks using the FlyteRemote functionality of the Flytekit Python SDK can easily navigate to any execution in the UI, copy the Flyte URL of the inputs or outputs of any Task, and pull this data directly into a Jupyter notebook.
Users of FlyteRemote can iterate locally or in a hosted workspace, then create remote executions on the Flyte cluster which are versioned and reproducible. This system of working allows for multiple teams whose outputs depend on one another (i.e. a Data Science team leveraging the latest results of a data pipeline), to seamlessly work together.
Conclusion
Flyte solves the reproducibility problem for workflows by wrapping tightly coupled artifacts, code, infrastructure, and configuration into a system with integrated compute and strong support for third-party services through Agents. Flyte’s abstractions - such as its Pythonic interface, declarative infrastructure, container management in code, and abstracted data flow - support reproducibility while mitigating the overheads present in other reproducibility techniques. This in turn enables the system to provide a range of developer-friendly features that can only be delivered by a fully-reproducible framework, like caching, remote debugging, and separation of concerns through Task sharing and Workflow parameterization.
The next blog post in this series dives into Union, the AI platform built on top of Flyte, and shows how it can be used to achieve the holy grail of reproducibility - seamless traversal of the end-to-end AI lifecycle.
Disclaimer: The creators of the Flyte open source project founded Union, which continues to heavily support the development of Flyte.